iOS应用开发:开发一款AI语音记账软件(基于 Qwen Omni)
/ 27 min read
提示:开发iOS应用需要使用Mac电脑,并下载Apple的官方集成开发环境(IDE) —XCode。所以如果你只有Windows电脑,这期教程可能你没法进行。
1. 项目概要
本期教程我们来尝试不写一行代码开发一个iOS应用,用户可以通过语音的方式来实现输入要记账的内容。AI会自动解析你的语音输入,分析出当中的购买的类目的描述、价格, 并且自动实现分类。
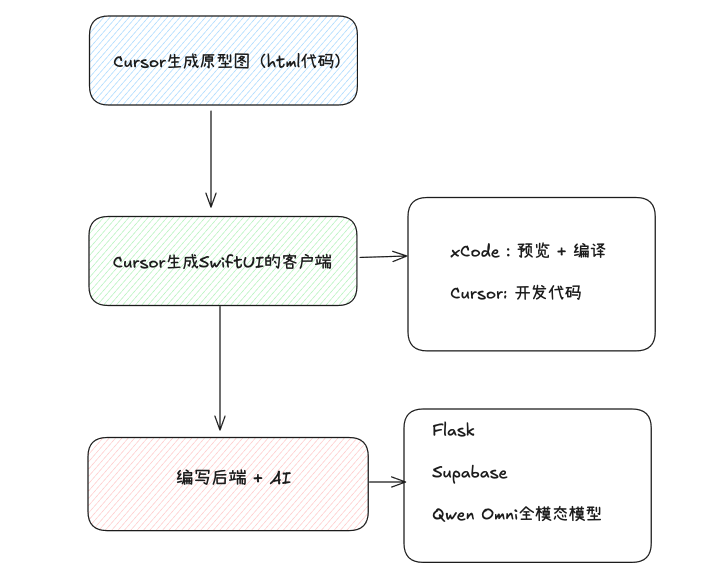
通过这个教程,你将会学习到:
1. 使用Cursor生成产品的原型图
2. 使用Cursor自动编写SwiftUI的代码,开发iOS应用
3. 使用Python框架Flask + Supabase编写后端,并且接入Qwen Omni的全模态模型
需要说明的是,使用cursor开发一个具备完整前后端功能的iOS应用,整体的难度要比web开发是要大不少的,所以大家要有一定的心理预期。特别是在后端接入的部分,debug的过程很长。这个视频的当中你也会看到不少我用Cursor去 debug的技巧,同时我也会教给大家如何的去梳理一个后端技术的流程。
2. 生成项目原型
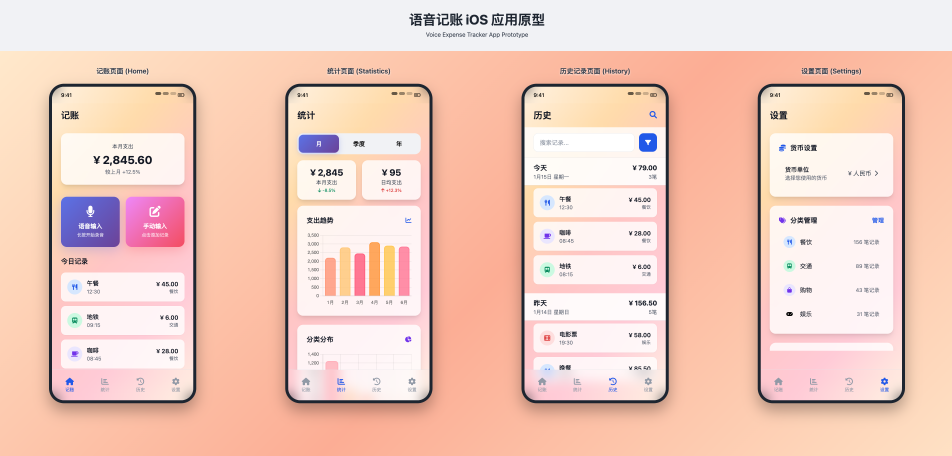
这一小节我们首先来使用Cursor生成对应的基于HTML代码的原型图。需要注意的是,即使是同一套提示词,AI生成出来的原型图也可能会有差异,AI生成后如果和自己的预期有差异的,需要和AI沟通反复调整。
大家也可以直接下载我生成好的原型图文件,直接跳到第3部。
为什么要先用使用Cursor生成原型图?
这在我们之前小程序的几期课程中有使用到,我们首先会让Cursor + Cluade的模型帮我生成HTML的原型图。生成原型主要有2个好处:
• 帮助我们理解项目样式和交互
• 帮助之后Cursor能够使用SwiftUI复刻我们的原型
创建一个空文件夹 prototype,拖入到Cursor中打开这个文件夹。使用Claude-4- Sonnet的模型 +Agent模式,在Agent模式下输入下面提示词:
项目描述:
开发一款语音记账iOS应用,项目总共有4个tab:记账/统计/历史/设置。
1. 记账:主界面为记账页面,顶部会显示本月支出,下方会有两个按钮,分别是语音输入和手动输入按钮,下方会显示今日的的记录历史。用户长按语音输入后,能够录音。点击手动输入后,弹出popup要求用户输入金额、标题、时间(默认当前时间)和选择分类
2. 统计:统计页面可以切换月/季度/年,然后显示对应的支出情况。并且显示两个柱状图,分别是趋势图(显示用户的花销,按时间顺序)和分布图(显示用户分类花销,从高到底)
3. 历史:按天显示历史记录
4. 设置:用户可以选择货币单位(人命币、美元、欧元)、对分类进行管理(真删改查)、对数据实现管理(有导出CSV数据的按钮,和清楚所有数据的按钮)。
请按照以下步骤完成所有界面的原型设计:
1. 用户体验(UX)分析任务:分析该 App 的核心功能与用户需求,确定主要交互逻辑。
要求:深入研究播客应用的用户行为,聚焦于发现、播放、订阅及社交分享等关键场景,确保交互流程直观、高效,并符合用户习惯。
2. 产品界面规划角色:产品经理
任务:定义 App 的核心界面,构建合理的信息架构。
要求:设计清晰的界面层级和导航体系,确保用户能够快速访问主要功能,同时保持整体结构的简洁性和可理解性。
3. 高保真 UI 设计角色:UI 设计师
任务:基于真实的 iOS 设计规范,打造现代化的高保真界面。
要求:严格遵循 iOS Human Interface Guidelines严格遵循 iOS 人类界面指南
注重视觉设计的统一性,包括色彩搭配、排版规范及图标风格。
使用真实的 UI 图片(可从 Unsplash、Pexels 或 Apple 官方 UI 资源获取),避免使用占位符图像,确保设计具备良好的视觉体验。
4. HTML 原型实现技术要求:使用 HTML + Tailwind CSS(或 Bootstrap)开发所有原型界面。
集成 FontAwesome(或其他开源 UI 组件)以提升界面的精美度和真实感。
代码结构:每个界面以独立 HTML 文件形式存储,例如 home.html、profile.html、settings.html 等。
index.html 作为主入口,不直接包含所有界面的完整代码,而是通过 <iframe> 嵌入各界面文件,并在 index 页面中平铺展示所有页面,避免使用链接跳转。
真实感增强:界面尺寸需模拟 iPhone 15 Pro 的屏幕规格,并应用圆角设计,以贴近真实移动设备的外观。
5. 交付物提供完整的 HTML 代码,确保其可直接用于开发阶段。
代码文件结构清晰,命名规范,便于开发团队理解和后续维护。
注意事项:所有设计和代码实现需符合现代移动应用的标准,兼顾视觉美观性、技术可行性以及未来的可扩展性。稍等片刻后,AI应该就会生成这样的原型图。当然如果有和自己的预期不太符合的,我们需要进一步和Cursor沟通实现调整。
3. 开发iOS客户端前端部分
在进入这部分教程之前,如果你的电脑上还没有安装XCode,你需要先到App Store中安装XCode。

3.1 新建项目
在Mac中下载XCode,打开Xcode,并点击 [Create New Project] 创建一个新的项目

我们要开发的是iOS App。选择平台为iOS,选择应用为App。
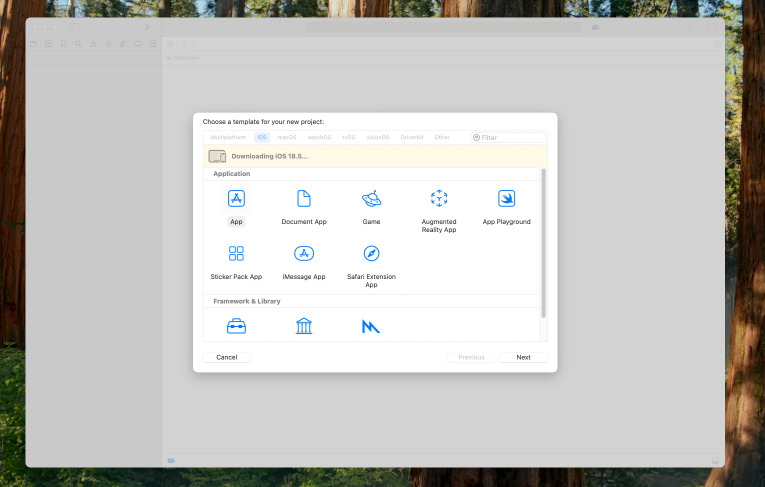
在 Product Name 中填入对应的产品名称,并在storage 中选择SwiftData。点击 【Next】,确认保存的文件目录即可。
什么是SwiftData?
SwiftData 可以帮你做到:
• 把数据保存在本地(如:用户的记账记录、待办事项、草稿等)
• 支持自动存储、查询、删除和更新数据
• 和 SwiftUI 无缝配合,比如你可以用 @Query 实时绑定界面数据
这个时候你就创建成功了你的第一个iOS应用。
3.2 用Cursor开发前端
3.2.1 基于原型图生成前端代码
想刚才新创建的项目文件夹拖动到Cursor中,用Cursor打开项目:
将我们上一步创建好的原型图的文件夹拖动到项目根目录下,修改文件夹的名称为 prototype,表示这是原型图页面。
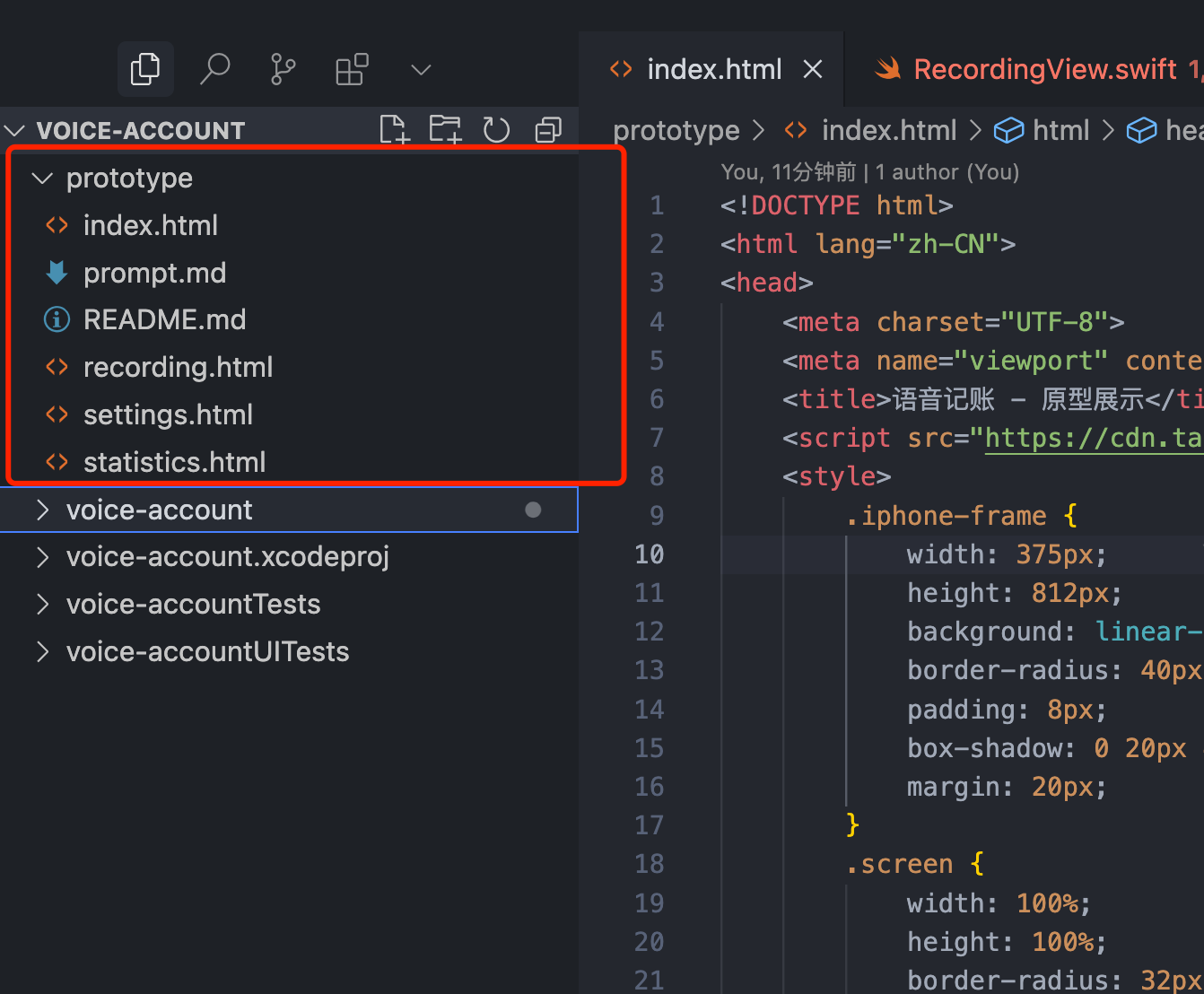
接下来在Cursor的Agent模式下输入对应的提示词,使用 claude-4-sonnet-thinking 的模型。等待AI生成完成
请你根据 @/prototype 下面的原型图,创建对应的iOS页面,在 @/VoiceAccount 文件夹下,创建对应的app页面。目前分别有4个页面,要求尽可能的还原样式。注意 @index.html 不用还原,它是一个概览页面,只需要还原其他4个页面就好。@文件夹和文件的操作需要自己手动选择,直接复制粘贴可能会失效哦!
3.2.2 优化+修改bug
注意:因为AI生成有一定的随机性,所以你遇到的报错信息和UI不一致的地方可能和我不太一样,你需要根据自己的实际情况和报销信息进行修改,建议看我的视频学会方法,而不是完全看下面的文档。
原则是:
1.如果有报错,将报错信息复制给Cursor。
2. 如果有和预期不一致的地方,描述清楚你希望AI修改的地方。越精准越好
等待AI创建成功原型图后,大概率你会和我视频中的一样,有几十个报错信息。这些报错属于编译错误。
等待AI创建成功原型图后,大概率你会和我视频中的一样,有几十个报错信息,这些报错属于编译错误。出现这个错误主要有两个原因:
1. Swift 是强类型+编译型语言,容错率低。
2. Cursor对于SwiftUl 的语法、作用域、结构等掌握不如JavaScript或者Python等语言
好在其实在XCode中明确给出了报错信息,遇到这些报错我们可以尝试两种办法让 Cursor实现修改:
1. 鼠标右键然后点击复制,一个一个复制报错信息给到Cursor
2. 直接截图给到Cursor这些报错信息
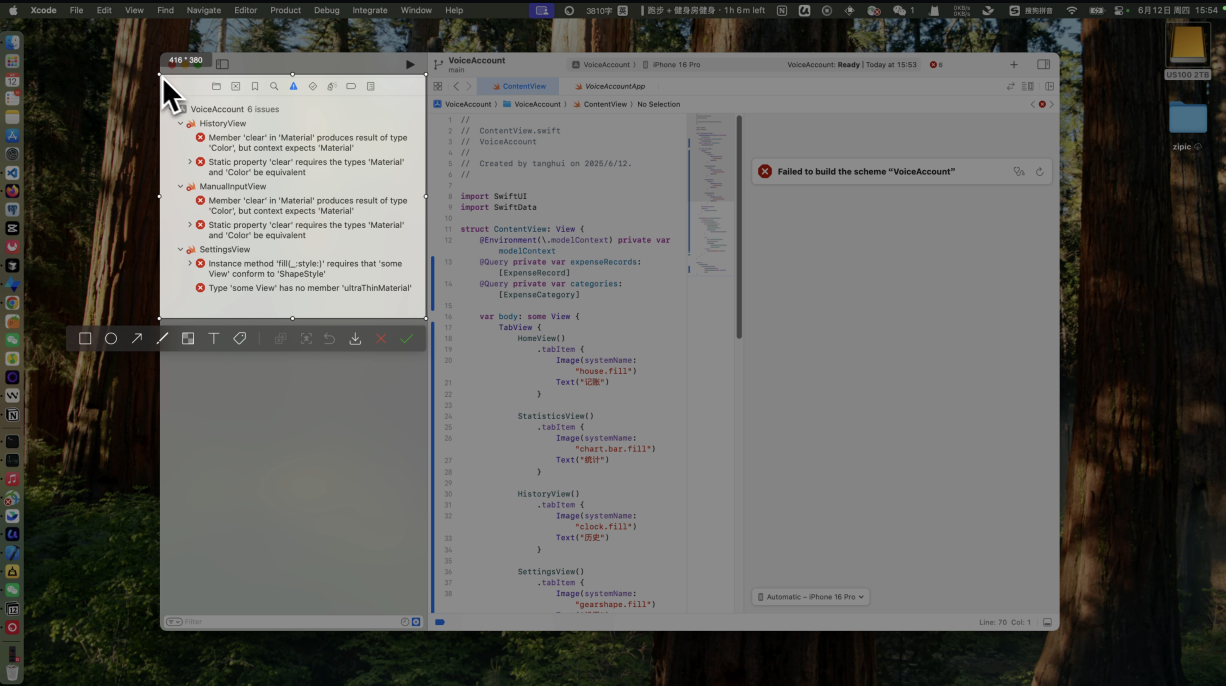
如果顺利的话,Cursor解决完成所有的报错信息后,你就可以点击 ContentView 这个页面,预览我们的项目成功跑起来了。
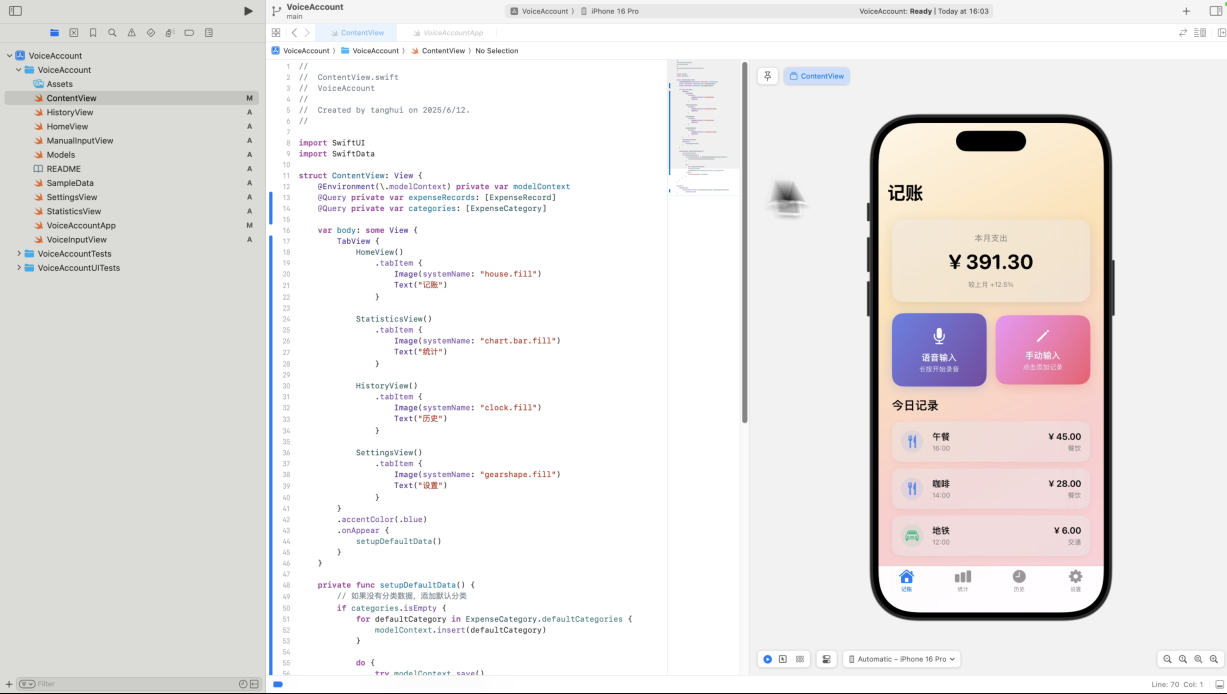
开始优化
之后我们就可以进入到真实的优化中,我们用Cursor做了多处的优化。注意:你需要优化的点可能和我们不太一样,需要根据你自己AI生成的实际情况调整,下面的提示词只是作为参考。
• 优化1:
• 提示词:
优化:1. 现在有很多的假数据,请你修改成为真实的本地存储的数据2. 分类管理处添加新分类的时候,没有办法编辑分类名称和对应的icon,我们选择icon和icon的背景色• 优化2:
• 提示词:
目前这两个页面的统计图的柱状图有显示异常:1. 支出趋势有假数据2. 分类分布会超出高度,并且x轴的柱子需要对其最底边• 优化3:
• 提示词:
有几个问题:1. 季度现在统计柱状图显示异常2. 柱状图的柱子上方增加对应的数字,最好能增加用户的交互3. 在设置页面切换货币单位后,所有的货币单位都应该实现修改• 优化4:
• 提示词:
设置页面的导出CSV数据功能没有完成,我希望点击后能够将所有的本地数据导出。4. 初始化Flask + Supabase
iOS客户端的前端部分开发完成后,接下来我们来开发后端部分。首先我们需要对这个产品的后端逻辑实现分析,最终我们产出了这样的一个后端流程图。
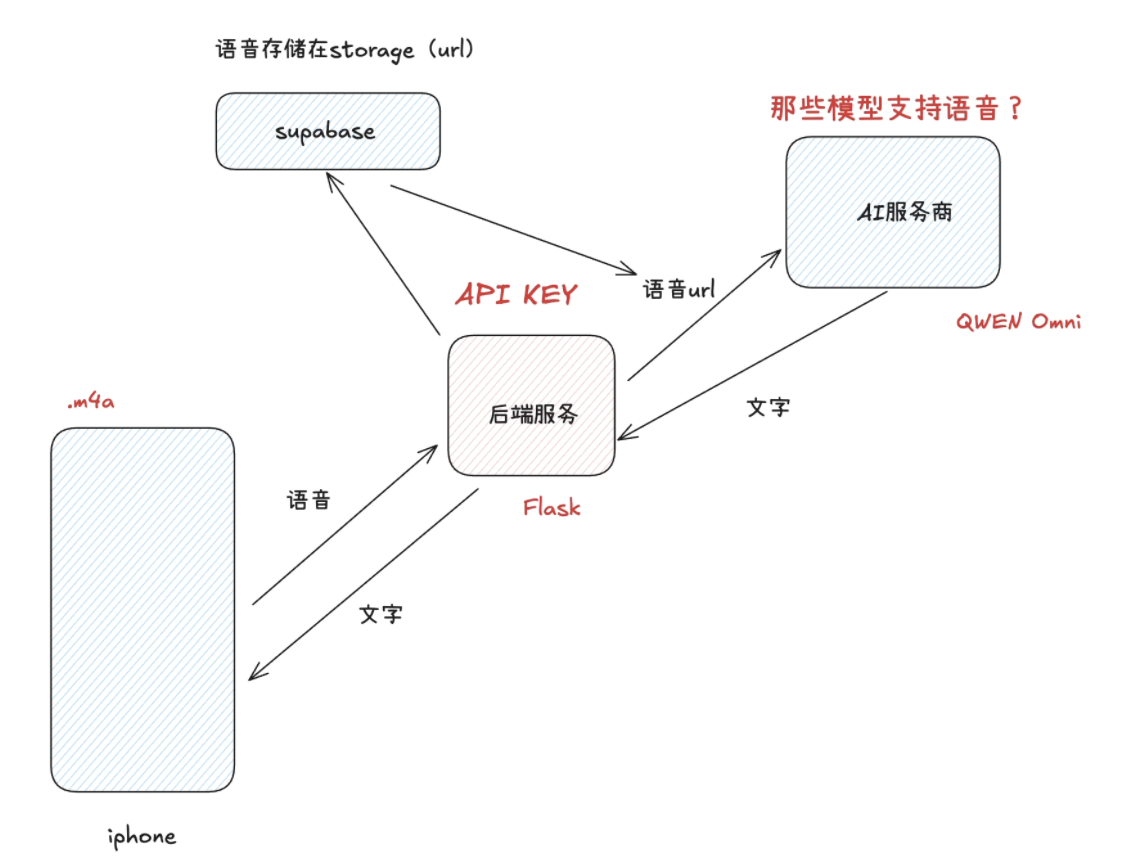
经过技术选型和调讲,我们最终选定了这样的技术方案:
1. 后端框架使用Python的Flask
2. 用户录音存储服务,我们使用supabase的Storage实现存储
3. 使用Qwen Omini模型实现音频的AI解析工作
4.1 初始化Flask
1. 创建一个新的文件夹,叫做 VoiceAccountServer
2. 用Cursor打开刚才创建好的文件夹
3. 在命令行中创建虚拟环境
• 终端命令
python3 -m venv venv4. 激活虚拟环境
• 终端命令
source venv/bin/activate5. 安装flask
• 终端命令
pip install flask安装成功后,在Cursor的Agent模式下输入以下提示词,让其创建一个接口
• 提示词:
创建一个flask接口,能够返回hello flask6. 在命令中输入 python app.py,运行起来Flask项目
• 终端
python app.py注意,这里要在虚拟环境中运行。注意前面需要有 venv 的显示字样。
问:为什么要使用虚拟环境?
答:虚拟环境让你在每个项目中使用独立的 Python包,不会互相影响,也不会污染系统环境。
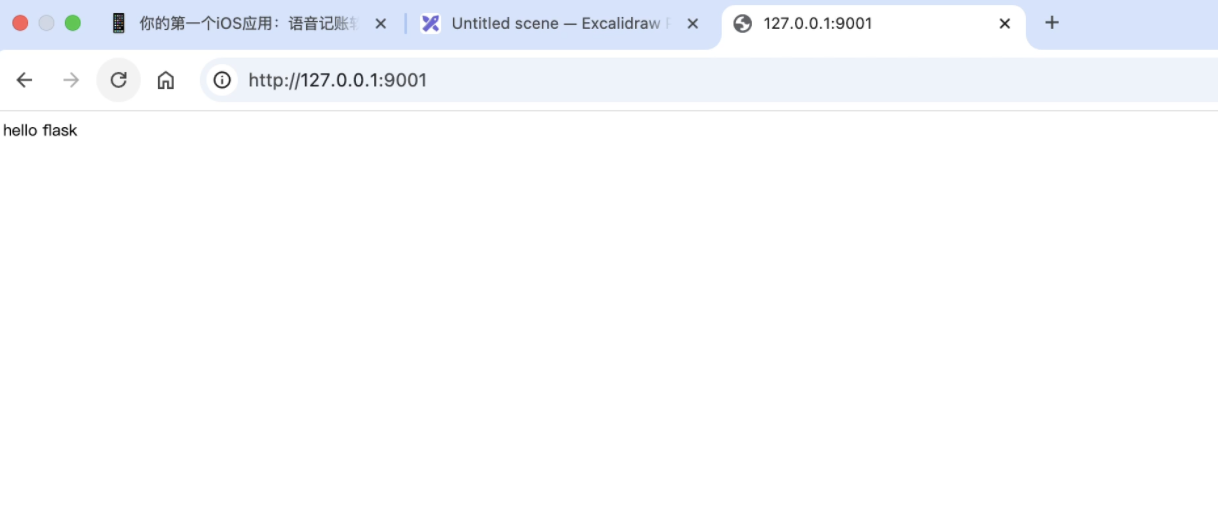
然后你可以访问 http://localhost:5000/(端口需要根据实际调整,我项目中修改成为了9001端口,默认应该会创建5000的端口)
4.2 接入Supabase
接下来我们来接入supabase,用于保存我们用户的录音功能。
1. 新建supabase项目
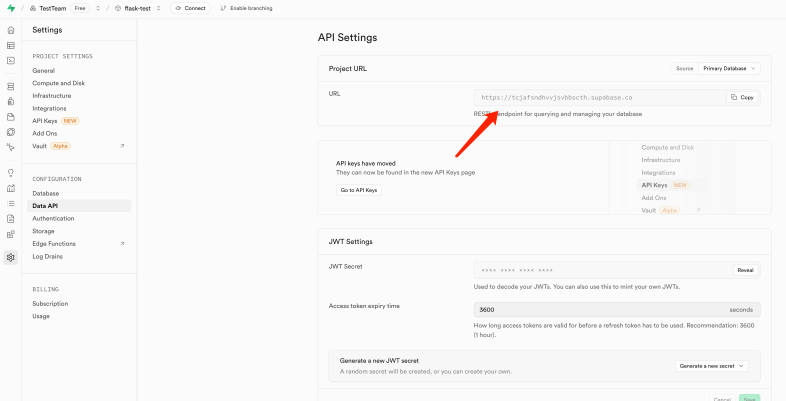
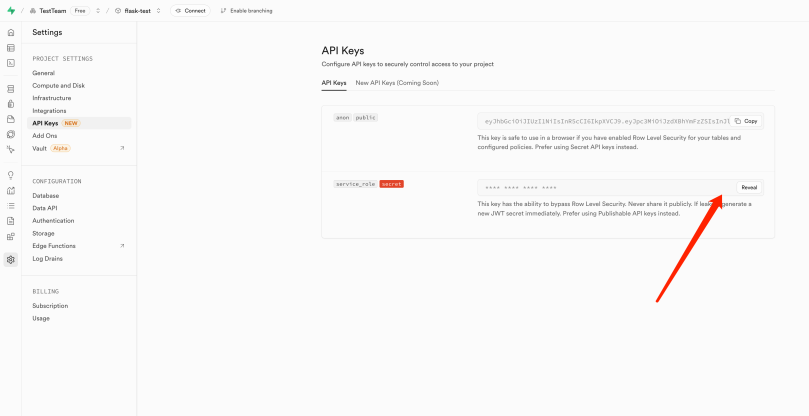
新建supabase项目,获取到对应的Project URL和服务端私钥
• Project URL
• 服务端私钥
2. 创建环境变量文件
在 /server 目录下,创建一个 .env 文件。将刚才获取到的项目url和服务端私钥填入。
SUPABASE_URL=your_project_urlSUPABASE_SERVICE_ROLE_KEY=your_service_role_key同时在项目的根目录下创建一个.gitignore文件,用于隐藏掉Git对应.env 文件的版本管理。避免该隐私文件被上传到了Github上。
3. 让Cursor接入Supabase
提示词:
在`app.py`中获取`.env`中的环境变量,并初始化supabase。`SUPABASE_URL`和`SUPABASE_SERVICE_ROLE_KEY`为supabase的Project URL和服务端私钥,使用服务端私钥初始化.
并且新建一个`/supabase-test`接口,该接口通过`supabase.auth.admin.list_users`获取用户数量。来测试是否接通supabase4. 重新安装依赖
在命令行中(venv的虚拟环境)输入一下命令,更新对应的环境变量:
pip install -r requirements.txt5. 启动项目并测试
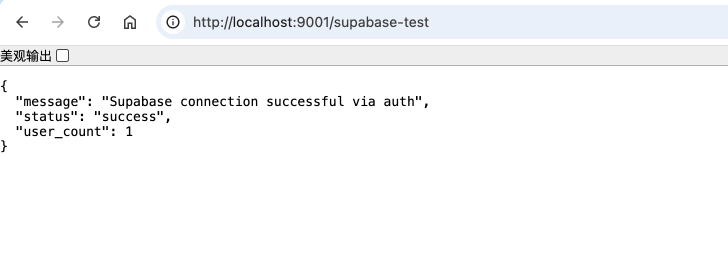
重新在命令行中输入python app.py,运行起来项目。然后在supabase中点击【Add user】添加用户。创建一个新的用户
然后访问 http://localhost:9001/supabase-test , 如果顺利你会发现你的Flask应用成功连接了Python。
5. 开发后端业务
上一步我们只是把后端的基础能力和框架搭建起来了,接下来我们来买现后端的业务需求。这一部分会比较难,同时提示词也会比较专业。
5.1 优化文件夹结构
在开始之前,我们先把客户端代码和后端代码放到同一个父文件夹中,然后用Cursor打开:
1. 父文件夹是 VoiceAccount
2. 客户端代码的文件夹修改成为 VoiceAccountClient
3. 服务端代码的文件夹修改成为 VoiceAccountServer
这样用Cursor同时打开 voiceAccount 这个父文件夹,Cursor就能同时拥有前后端的上下文,方便同时让Cursor修改。这算是一个小技巧。
5.2 文件上传服务
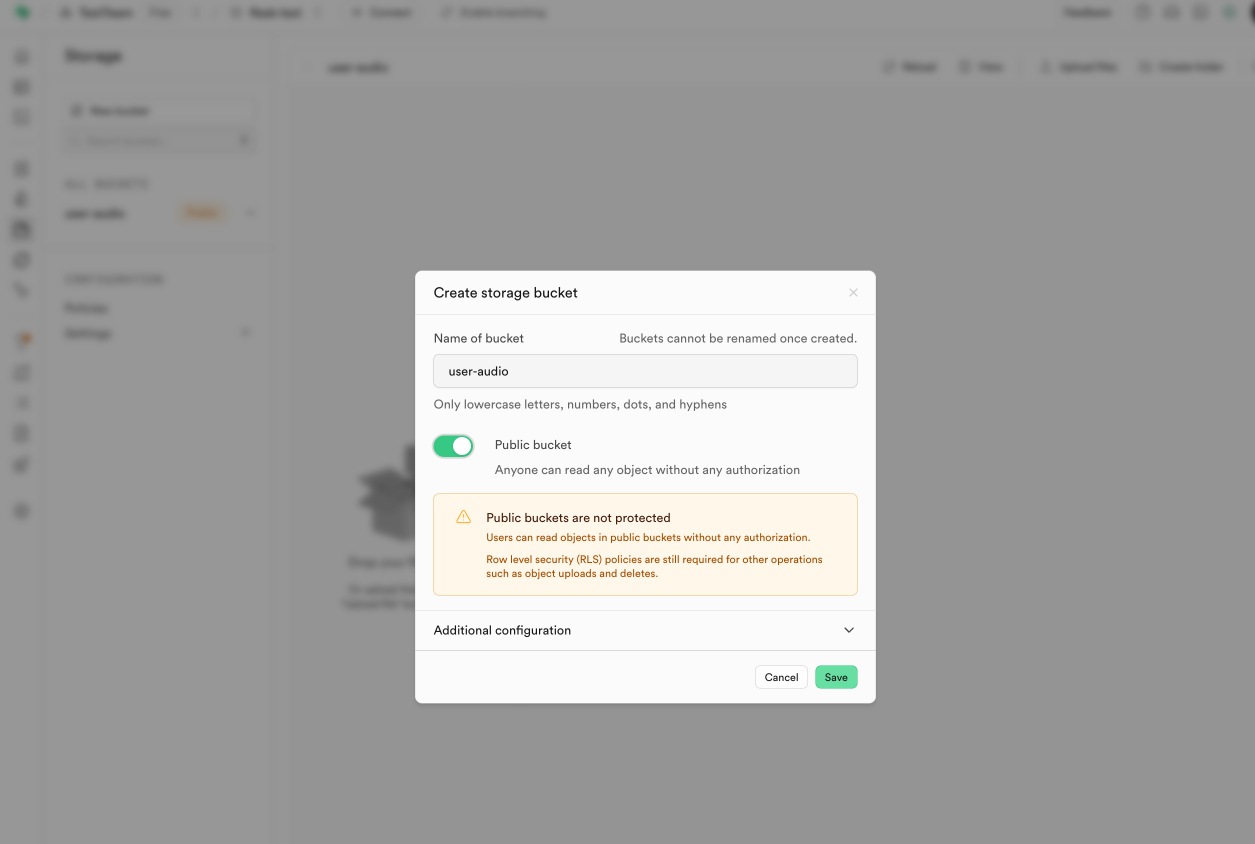
5.2.1 新建存储桶
在Supabase的Storage中点击【New Bucket】按钮,新建一个存储桶,叫做 user-audio。同时设置为Public bucket。
5.2.2 开发存储录音服务
现在我们来开发存储录音服务,当用户点击录音的时候,能够上传录音到supabase的 storage中,方便之后Al解析。
提示词:
1. 用户点击录音按钮后,需要实现录音,结束录音的时候,保存录音文件为.m4a的文件格式并发送给后端接口2. @app.py 中新增一个接口,用于接受录音文件,然后将录音文件保存到supabase的文件存储桶中,对应的bucket名称为user-audio。并且返回对应的url等Cursor修改成功之后,你可能需要安装一些依赖并重启一下Python的后端服务,打开终端,分别输入下面的命令:
cd VoiceAccountServer
source venv/bin/active
pip install -r requirements.txt
python app.py如果在终端看到项目运行起来了,那么就表示后端服务重启成功了。
这一步的调试我们需要编译,使用模拟器实现调试。
这个时候会出现一个具有真机功能的这样一个模拟器,我们使用它实现测试
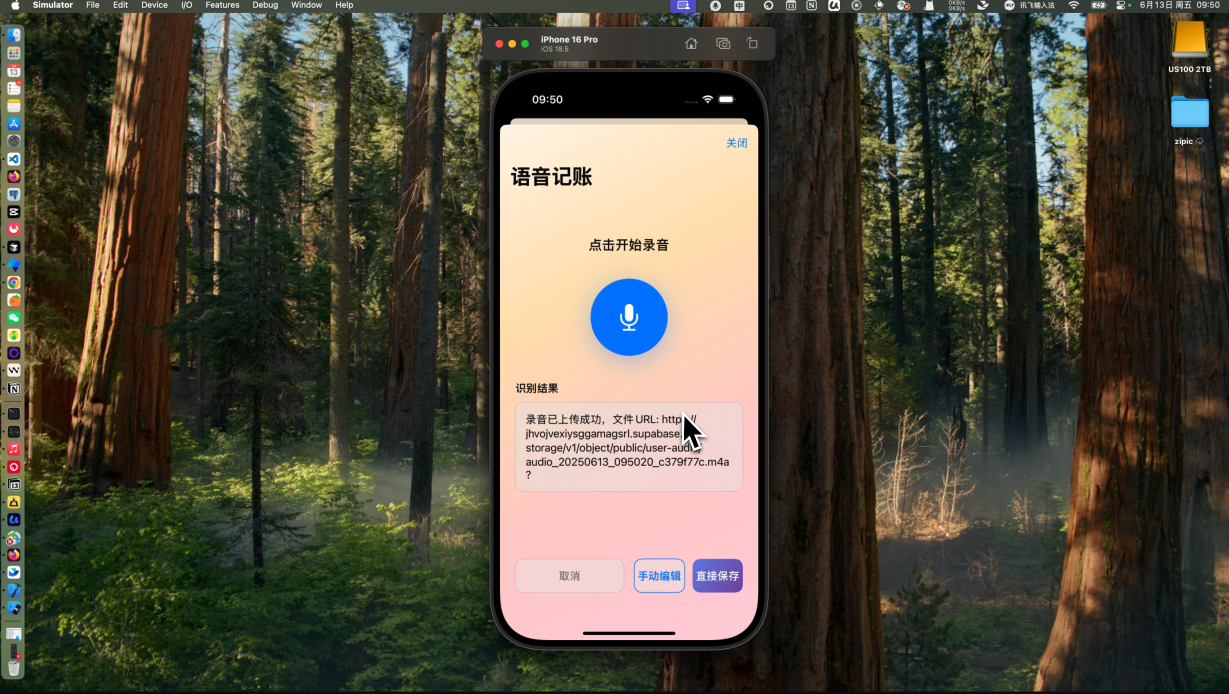
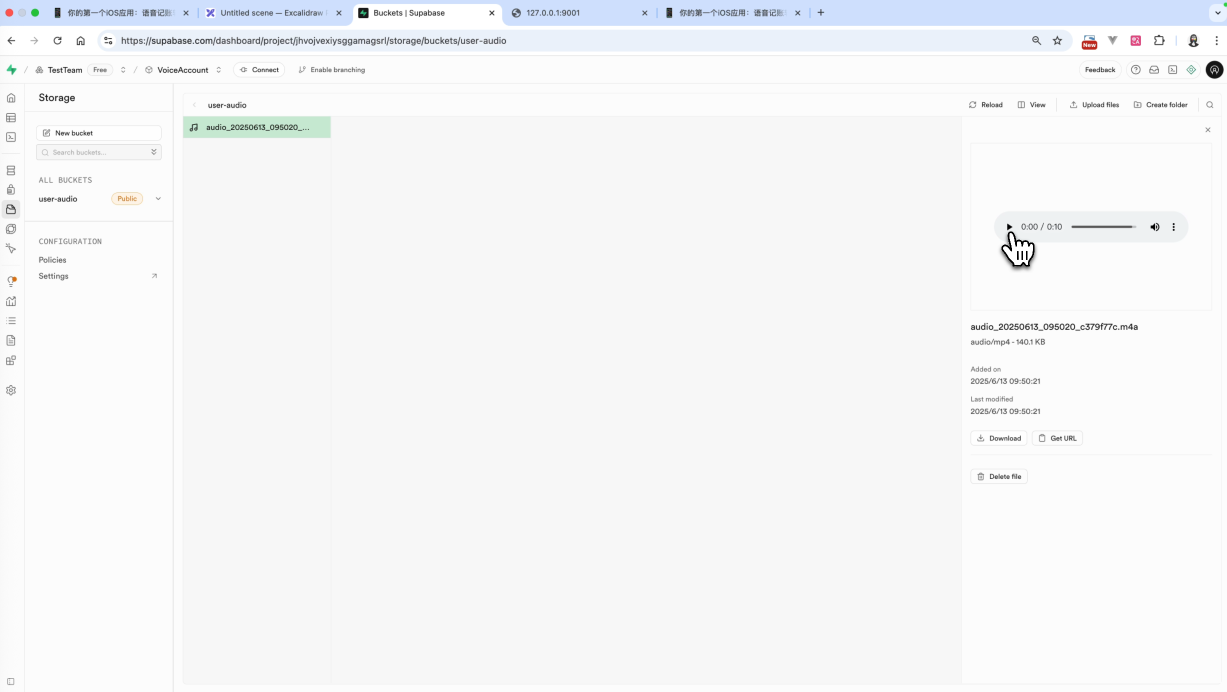
点击语音输入然后点击录音按钮。如果顺利的话,你就可以在supabase的storage中看到你刚才上传的那个音频文件了。就说明这个功能开发完成了。
5.3 接入后端AI服务
现在我们完成了录音的存储服务,并且获取到了录音的远程url。这个时候我们就可以来接入我们对应的后端服务了。也就是架构图中下面这部分。
5.3.1 选择模型 +获取API Key
我们选择阿里云百炼当中的【通义千问-Omni-Turbo】模型,这个模型是一个全模态模型,支持文本/图像/音频/视频的解析。
首先我们点击API-KEY,创建一个对应的API-KEY
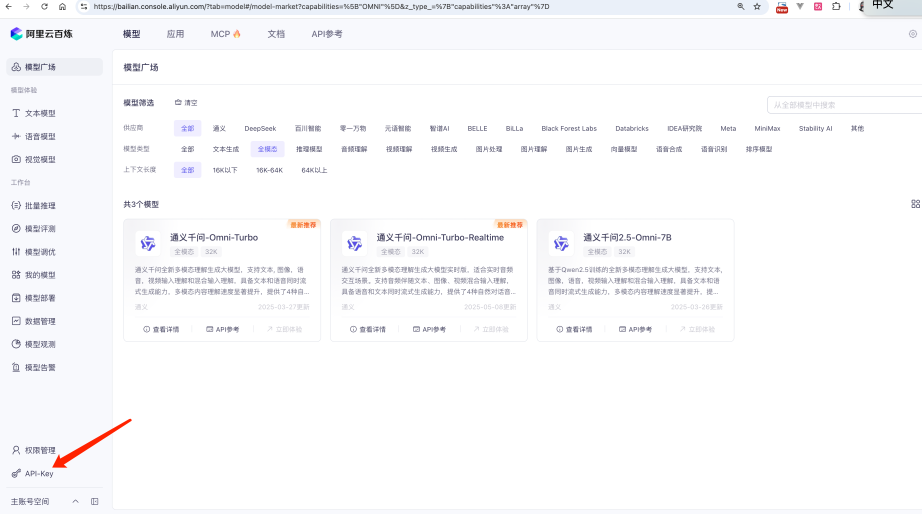
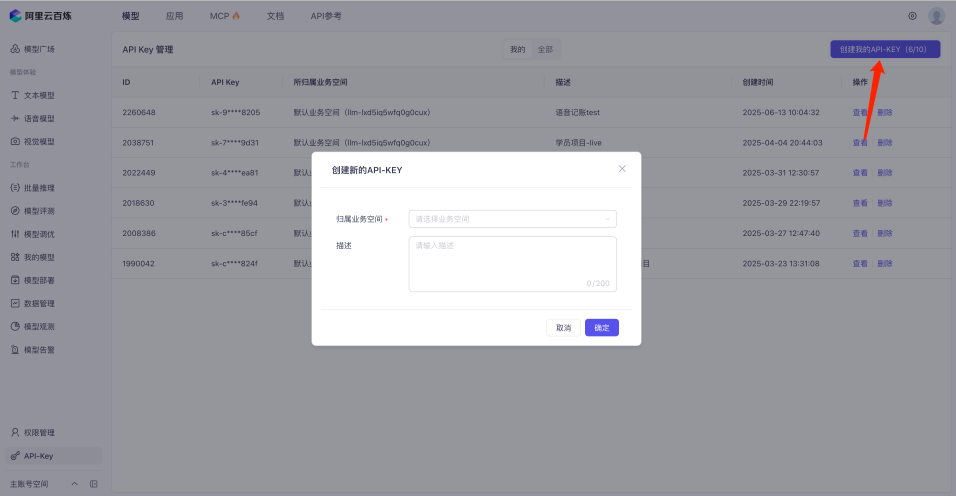
然后复制创建好的API KEY,将其填入到我们的 VoiceAccountServer/.env 文件中, 在.env中新增 DASHSCOPE_API_KEY,填入你刚才在阿里云百炼中获取到的API KEY
.env:
SUPABASE_URL=your_supabase_urlSUPABASE_SERVICE_ROLE_KEY=your_supabase_service_role_keyDASHSCOPE_API_KEY=dashscope_api_key5.3.2 开发AI解析功能
接下来我们进入到Qwen-Omini的API文档中,找到音频+文本输入部分的示例代码。这段代码能够作为Cursor接入AI功能的重要参考。
然后再Cursor中输入下面的提示词
• 提示词
```import osfrom openai import OpenAI
client = OpenAI( # 若没有配置环境变量,请用阿里云百炼API Key将下行替换为:api_key="sk-xxx", api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",)
completion = client.chat.completions.create( model="qwen-omni-turbo-0119", messages=[ { "role": "user", "content": [ { "type": "input_audio", "input_audio": { "data": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250211/tixcef/cherry.wav", "format": "wav", }, }, {"type": "text", "text": "这段音频在说什么"}, ], }, ], # 设置输出数据的模态,当前支持两种:["text","audio"]、["text"] modalities=["text", "audio"], audio={"voice": "Cherry", "format": "wav"}, # stream 必须设置为 True,否则会报错 stream=True, stream_options={"include_usage": True},)
for chunk in completion: print(chunk) # if chunk.choices: # print(chunk.choices[0].delta) # else: # print(chunk.usage)```
1. 请你参考上面的代码,在python中增加一个新的接口,用于将/upload-audio接口上传的语音url地址通过该接口的方式解析我们的记账明细,要求AI返回金额/标题/分类的json数组的形式,如果有多条需要返回多条。接口中需要上传语音url地址和客户端中保存的分类数据,方便AI自动选择对应的分类。
2. 客户端需要新增该接口的调用逻辑,当/upload-audio接收到语音url后立即调用该接口,并开始AI解析的状态提示,移除掉现有的url地址的显示,要求显示一个好看的AI解析中的动画效果。在接受到AI的返回值后呢,能够进行渲染我们记账的条目,并且用户能够自己编辑金额/标题/分类/时间(时间默认客户端当前时间),并实现统一保存等待AI增加完前后端的逻辑之后,我们就可以开始进行测试了。如果遇到相关的Bug,我们就像之前做的那样,把报错信息告诉Cursor。如果有相关的和预期不太符合的地方, 我们也把现在呈现的现状,以及我们的预期描述发送给Cursor,让Cursor来实现修改。
这一步我们的报错Debug的时间很久,大家可以查看我们的视频,看一下我是如何让 Cursor一步一步修改完成这些报错的。
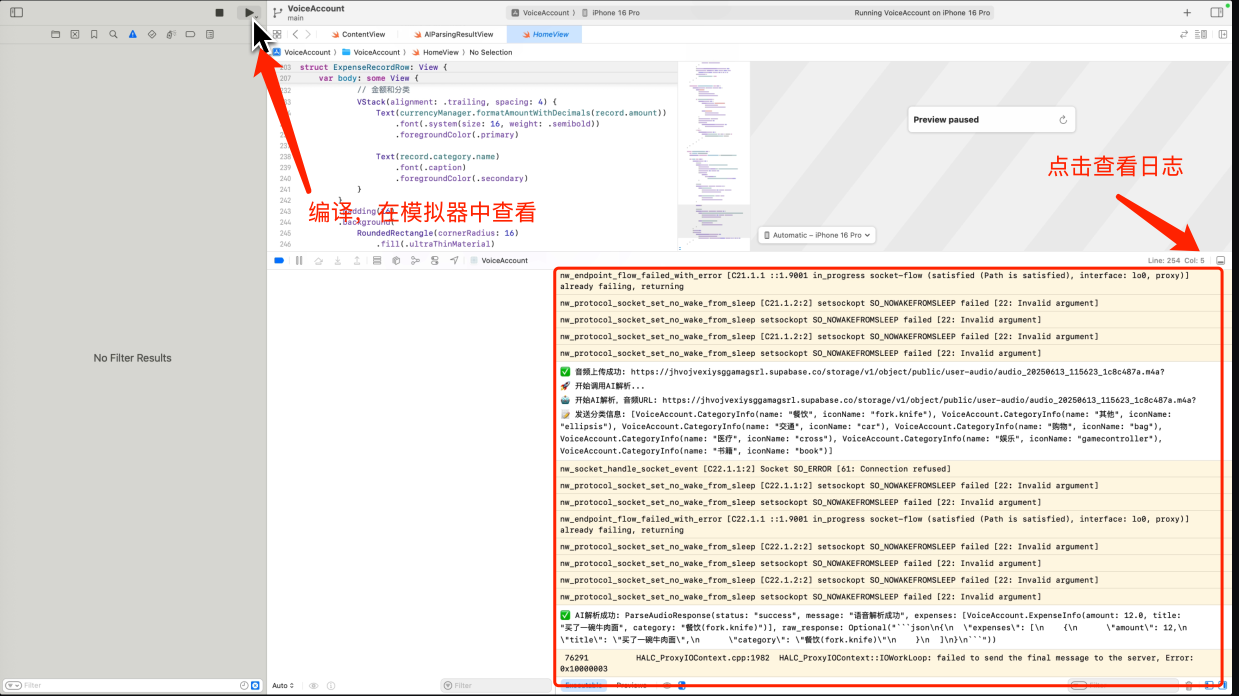
注意,这一步同样需要在模拟器中查看,点击编译按钮。你就可以打开模拟器。在调试过程中,注意打开控制台面板。来查看对应的日志信息,方便我们查看整个AI语音解析的流程。(如果你发现没有日志,你可以让AI添加上对应的日志信息)
5.4 增加Logo
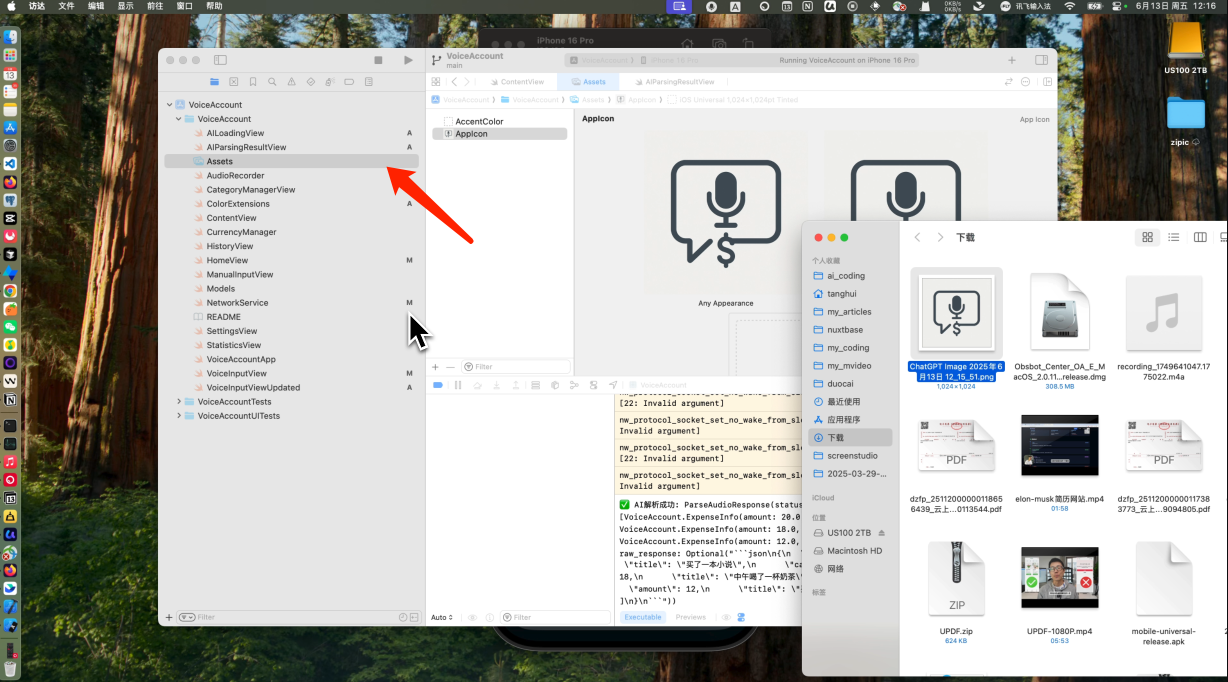
我们的产品现在还没有Logo,那么如何给产品添加上对应的Logo呢?也很简单,你只需要在XCode中点击Assets,然后拖入你自己创建好的Logo就好
注意Logo的规格是1024×1024,同时目前有3个Logo,分别代表下面几个意义。你可以根据自己的需要分别传入不同的Logo图片。当然在我们的教程中为了省事,就传入了同样一个Logo。

现在我们的记账的数据是通过SwiftData进行本地存储的。一旦用户更换了手机就无法查看记账的历史数据了。你可以尝试一下将记账的数据存放在supabase的数据库中,让AI 新增一个数据表,然后来编写对应的提示词帮你完成这个数据存放到数据库的逻辑吧!
如何实现真机调试?
如果你想实现真机测试工作,用你的iPhone连接到你的手机,同时需要在你的iPhone上开启开发者服务才行。在连接手机的时候,你会遇到两个问题,否则无法实现手机调试:
1. 需要在iPhone上开启开发者服务
2. 编译成功后,需要授权开发者证书才能够打开App
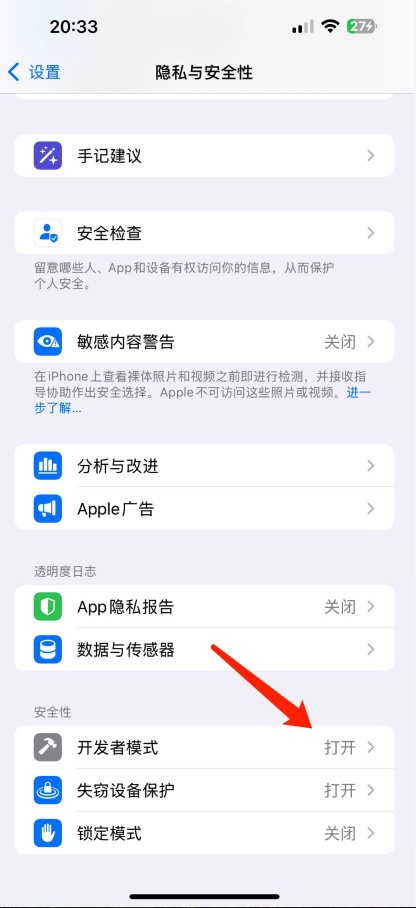
如何在iPhone上开启开发者服务?
1. 在【设置】中点击【隐私与安全性】
2.找到【开发发者模式】(Developer Mode),并打开
3. 手机会自动重后,并要求你验证
如何解决无法打开应用的开发者证书的问题?
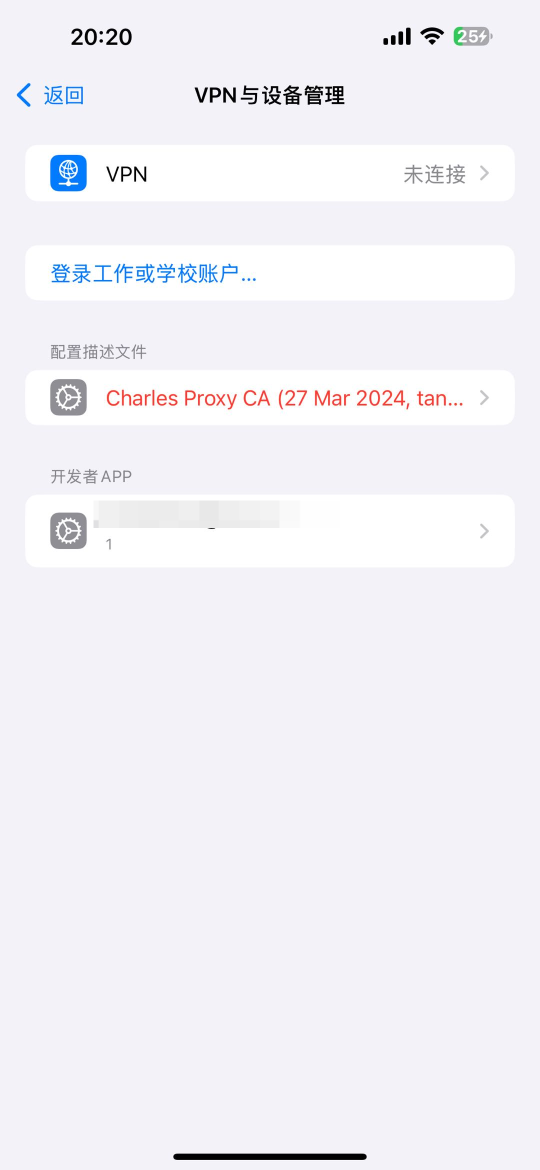
1. 在【设置】中搜索 【VPN 与设备管理】
2. 找到对应的证书
3. 信任开发者APP的对应的证书
同时你要修改请求地址,使用局域网的请求地址。
ipconfig getifaddr en0搜索项目中的 http://localhost,找到请求地址,将其替换成为IP地址,并确保你的手机和电脑处于同一个局域网下。就可以用有线连接你的手机进行测试了。
6. 项目源码
6.1 客户端代码(内含HTML原型图代码)
6.2 后端代码
6.3 iOS上架流程