Al毒舌电影小程序:DeepSeek 如何评价春节档电影?
/ 30 min read
这个教程为第一个实战教程,目前暂无手把手的视频教程。之后会补上!
一.作品展示
本期视频我们将会构建一个AI电影小程序!通过DeepSeek + Coze作为后端,来评价今年春节档的电影。
小程序首页会展示春节档的电影评分和票房,电影详情页面会请求Coze的后端 API,实现Al毒舌评论春节档的效果。并且你还可以通过聊天对话框和AI对话,了解这一部电影的更多细节。
• 小程序首页:展现春节档电影
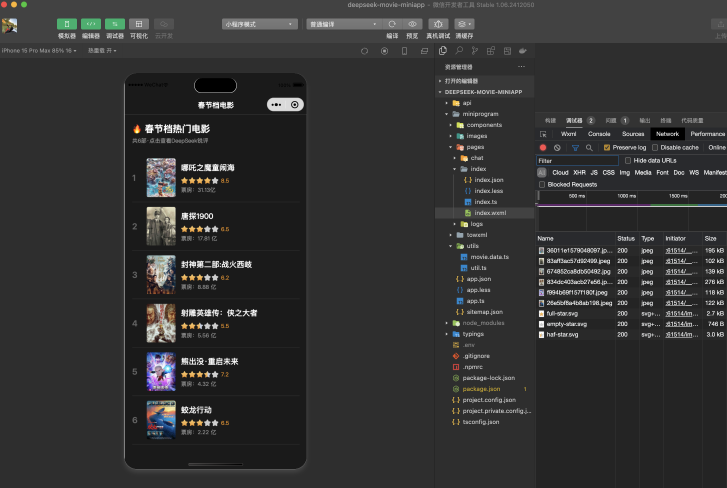
• 电影详情页:AI智能评价春节档电影+和AI对话
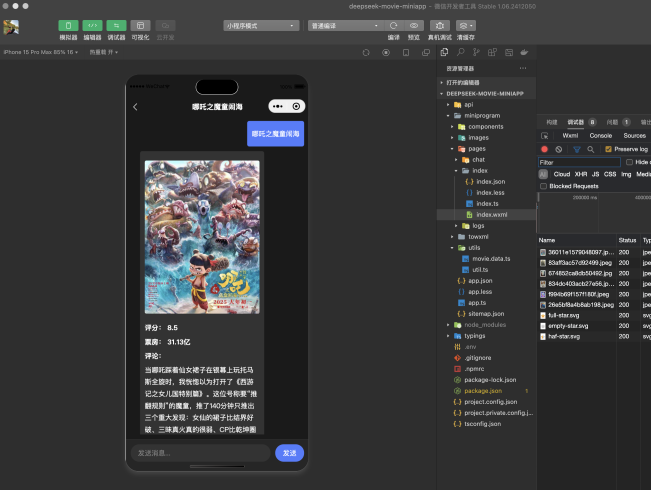
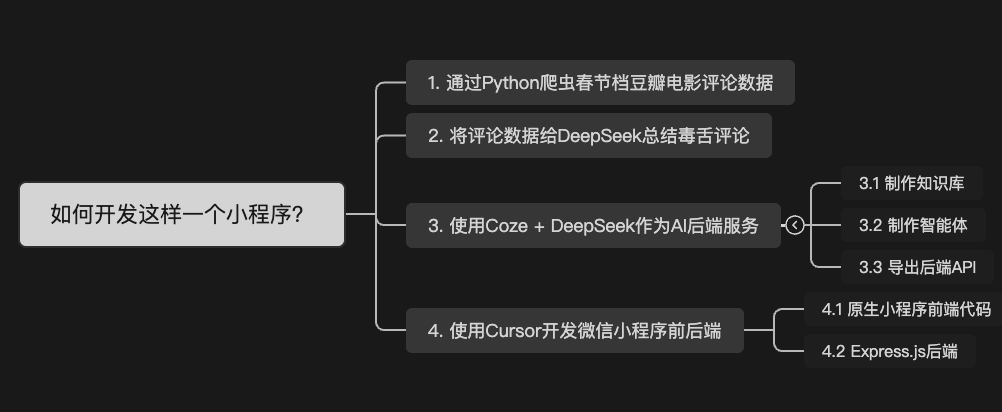
二. 项目流程
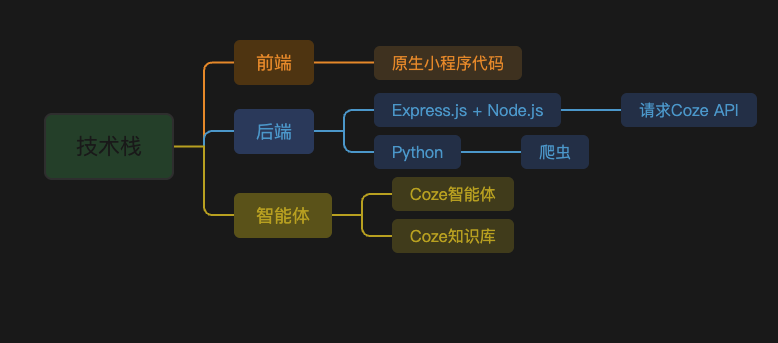
三. 有哪些技术栈?
四. 实战环节
提示:AI生成的prompt效果不一定100%稳定。如果通过我的prompt在Cursor中无法100%复现效果,你可以:
1. 自己主动的追问,来达到效果
2. 或者直接使用我给出代码
建议使用第一种方式!AI时代得学会主动和AI沟通,来达成自己想要的效果。
1. 爬虫豆瓣电影评论
1.1 使用Cursor编写爬虫代码
首先我们需要通过豆瓣电影获取到春节档电影的热门评论。这一步我们将使用Curosr来实现!
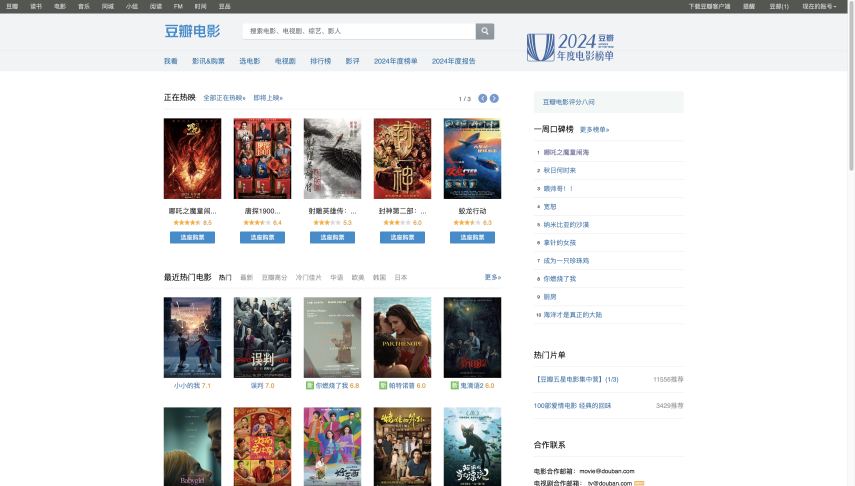
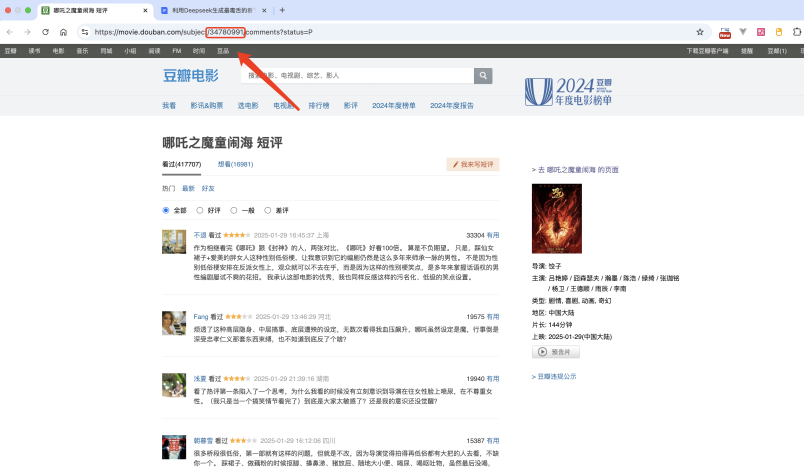
以哪吒为例,我们主要是获取的这个页面
(https://movie.douban.com/subject/34780991/comments) 的评论数据:
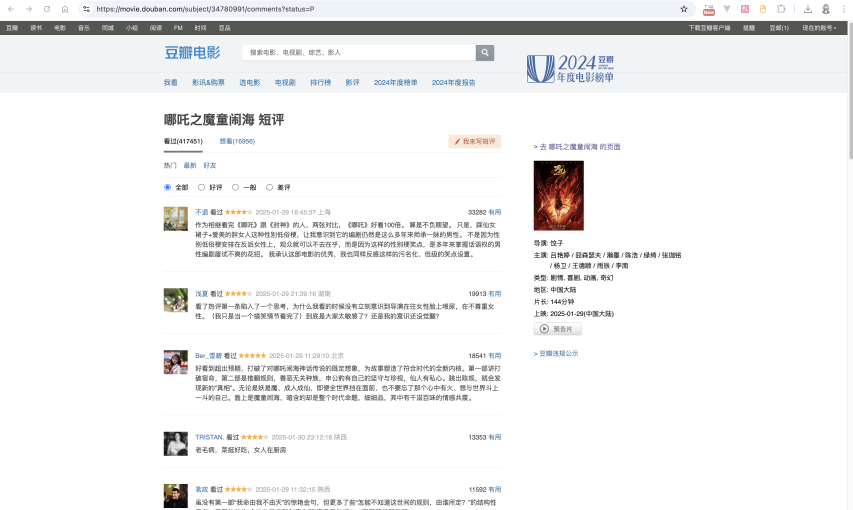
首先我们打开Curosr, 然后在COMPOSER中输入以下提示词:
完成一个获取豆瓣电影热门短评的python爬虫代码,命名为hot_comments.py- 在项目根目录直接创建文件并给出详细的代码- headers 给出 cookie 变量,我需要手动填写- 获取所有热门短评,max_page默认19你会得到下面所示的Python代码:
hot_comments.py:
import requestsfrom bs4 import BeautifulSoupimport timeimport randomimport jsonimport osfrom typing import List, Dict
class DoubanHotCommentsCrawler: def __init__(self): self.headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36', 'Cookie': '', # 需要手动填入你的豆瓣Cookie 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8', 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8', 'Host': 'movie.douban.com', 'Referer': 'https://movie.douban.com' } self.base_url = "https://movie.douban.com/subject/{}/comments"
def get_hot_comments(self, movie_id: str, max_pages: int = 19) -> List[Dict]: """获取指定电影的热门短评""" comments = [] for page in range(max_pages): url = f"{self.base_url.format(movie_id)}?start={page * 20}&limit=20&status=P&sort=new_score" try: response = requests.get(url, headers=self.headers) if response.status_code == 200: soup = BeautifulSoup(response.text, 'html.parser') comment_items = soup.find_all('div', class_='comment-item')
if not comment_items: print(f"第 {page + 1} 页没有更多评论") break
for item in comment_items: comment_data = self._parse_comment(item) if comment_data: comments.append(comment_data)
print(f"成功爬取第 {page + 1} 页,当前共 {len(comments)} 条评论")
# 添加随机延迟,避免被封 time.sleep(random.uniform(3, 10)) except Exception as e: print(f"爬取第 {page + 1} 页时出错: {str(e)}")
return comments
def _parse_comment(self, comment_item) -> Dict: """解析单条短评数据""" try: # 获取评论者信息 author = comment_item.find('span', class_='comment-info').find('a').get_text(strip=True)
# 获取评分 rating_span = comment_item.find('span', class_=['allstar50', 'allstar40', 'allstar30', 'allstar20', 'allstar10']) rating = rating_span['title'] if rating_span else "未评分"
# 获取评论内容 content = comment_item.find('span', class_='short').get_text(strip=True)
# 获取评论时间 time_str = comment_item.find('span', class_='comment-time').get_text(strip=True)
# 获取点赞数 votes = comment_item.find('span', class_='votes').get_text(strip=True)
# 获取是否购票 ticket_span = comment_item.find('span', class_='comment-info').find('span', class_='user-ticket') ticket = ticket_span.get_text(strip=True) if ticket_span else "未标注"
return { 'author': author, 'rating': rating, 'content': content, 'time': time_str, 'votes': votes, 'ticket': ticket } except Exception as e: print(f"解析评论时出错: {str(e)}") return None
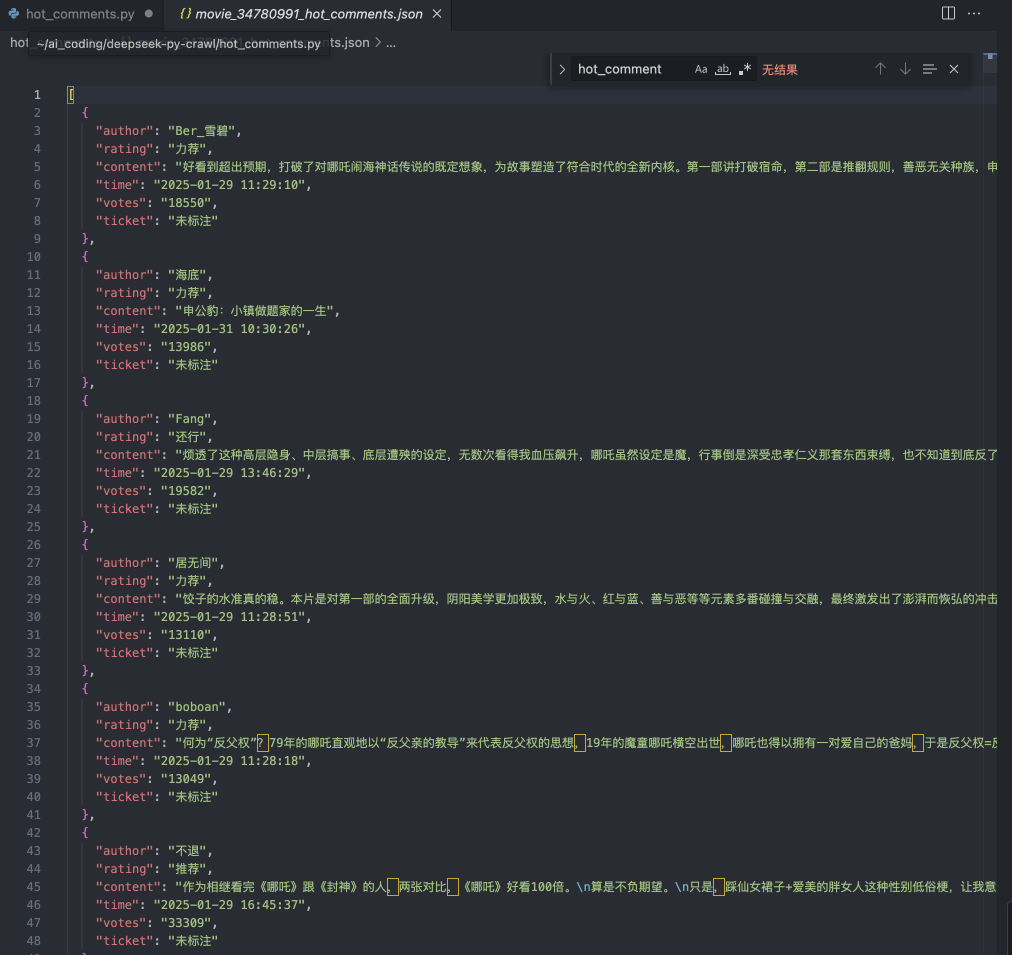
def save_comments(self, comments: List[Dict], movie_id: str): """保存评论到JSON文件""" if not os.path.exists('hot_comments'): os.makedirs('hot_comments')
filename = f'hot_comments/movie_{movie_id}_hot_comments.json' with open(filename, 'w', encoding='utf-8') as f: json.dump(comments, f, ensure_ascii=False, indent=2) print(f"评论已保存到 {filename}")
def main(): crawler = DoubanHotCommentsCrawler() movie_id = "" comments = crawler.get_hot_comments(movie_id) crawler.save_comments(comments, movie_id)
if __name__ == "__main__": main()这段代码中有2个需要你主动去修改的地方,这里有细节需要注意:
1. 增加cookie
首先我们需要在这里手动填入你的cookie,cookie是你用户身份的标识,填入了才能避免你的爬虫请求不会被豆瓣列为恶意请求给禁用掉。
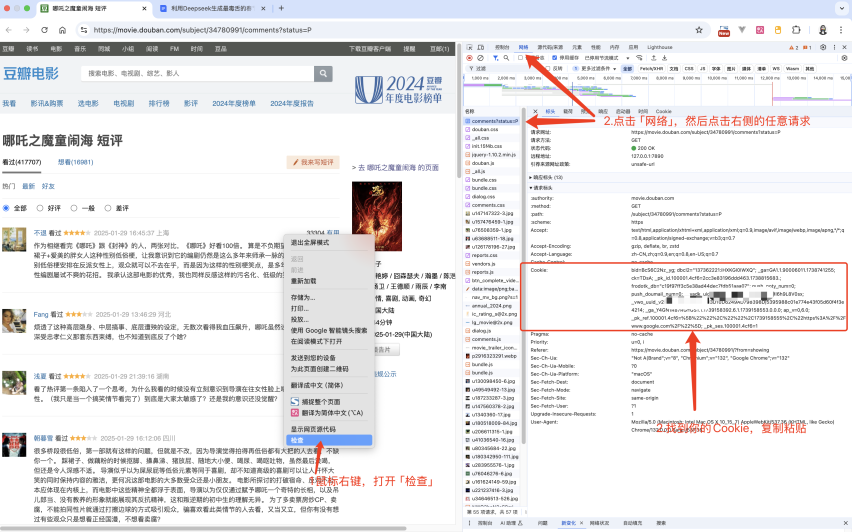
从浏览器中获取cookie的步骤可以参考下图
• 鼠标右键,打开「检查」
• 点击网络,然后点击右侧的任意请求
• 找到你的Cookie,复制粘贴到刚才代码中的地方
2. 增加 movie_id
第二步是需要我们获取电影的id,填入到下图所在的地方
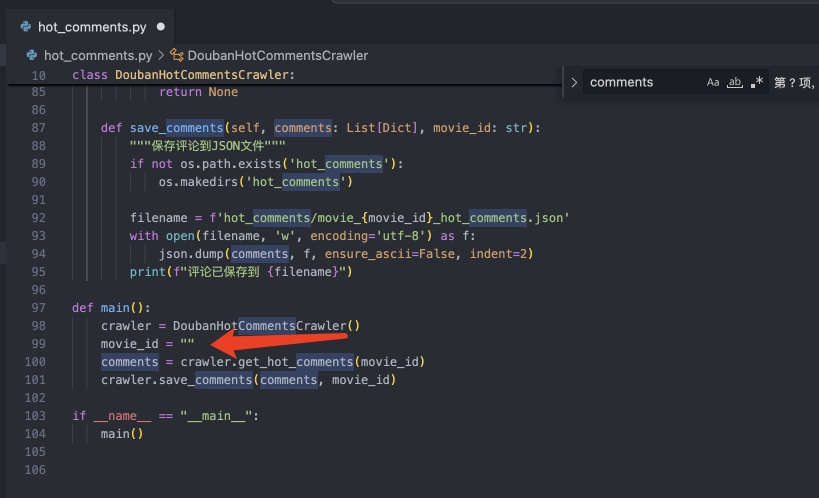
这一步很简单,因为豆瓣的电影id都是在链接上面公开可见的,以哪吒为例,这个 34780991 就是哪吒的电影id。复制并粘贴到刚才的代码中
到这一步我们就获取到了可以爬取豆瓣电影的Python代码!
1.2 运行Python代码,爬虫
1.2.1 安装依赖
接下来在Cursor中打开命令行,首先我们需要安装对应的Python依赖,因为我们的项目文件开头依赖了一些库。
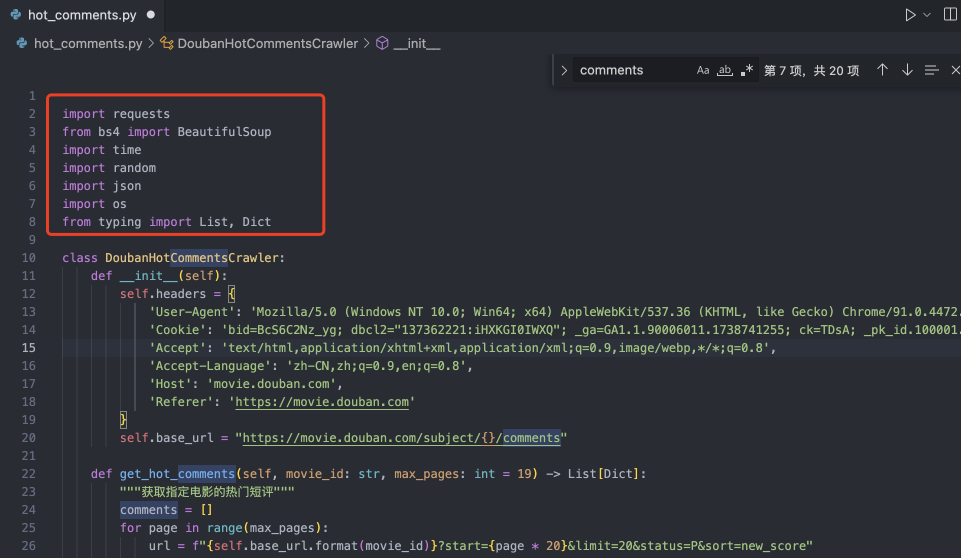
但是,我相信你不知道哪些库是需要安装的,因为有一些可能是Python标准库无需安装?那怎么知道我需要安装哪些库呢?很简单,在Cursor中问就好。你打开Cursor,然后提问:请你告诉我需要安装哪一些依赖?
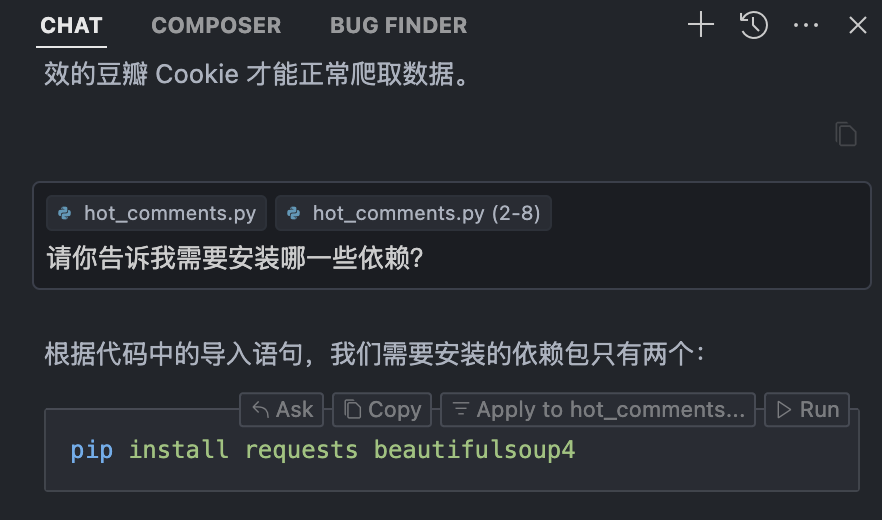
然后直接点击 Run 安装就好
1.2.2 运行爬虫代码
安装好依赖,我们就可以运行Python的代码,执行爬虫啦!
在Cursor中打开命令行,输入以下的命令执行爬虫代码
执行python命令:
python hot_comments.py如果顺利的话,你应该就能看到执行成功,并且生成的json文件也在目录下面了。
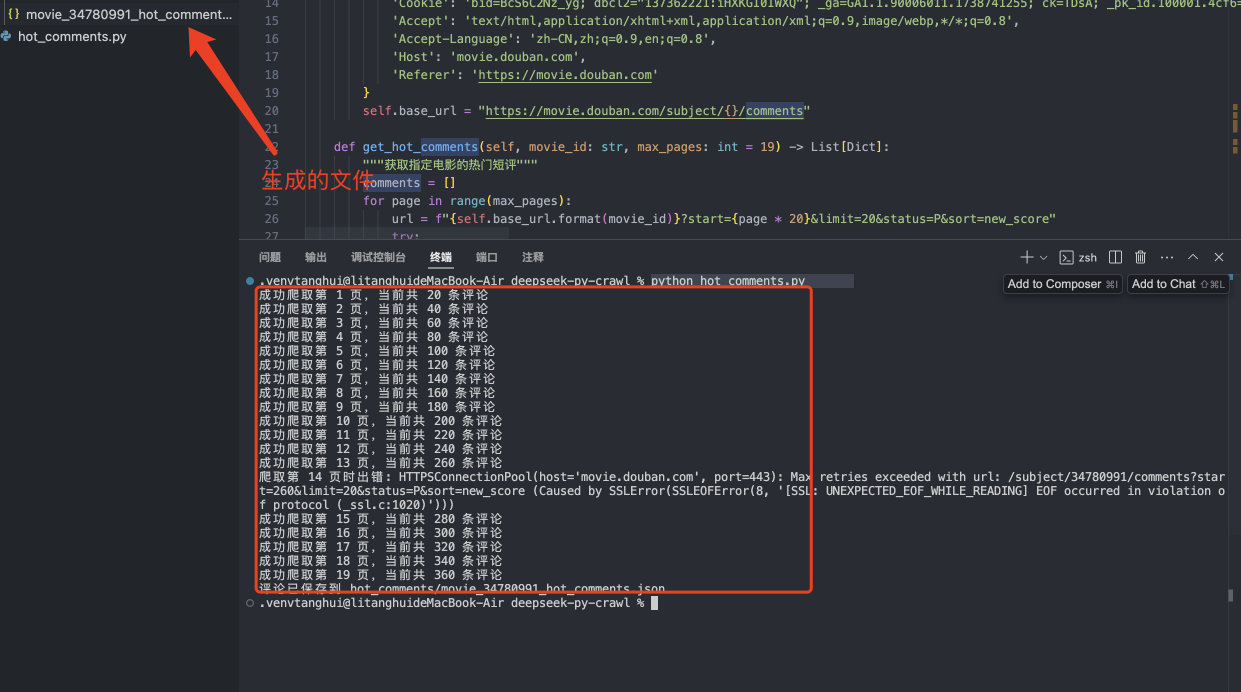
我们可以打开目录看一下,应该获取到了前20页的评论数据。如果你想要获取更多,可以修改爬虫代码里面的页码数。
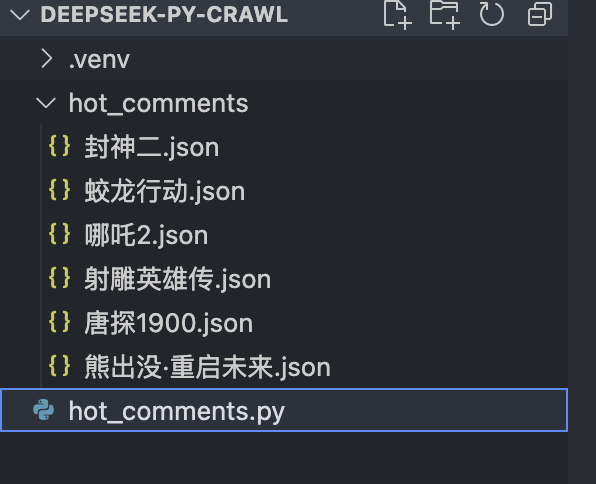
1.3 重复执行不同电影的爬虫
接下来我们可以重复执行不同电影的爬虫代码,只需要修改对应的电影id,然后将获取到的所有JSON文件,重新命名成为我们熟悉的中文电影名称。如图所示:
到这一步我们就基本完成了春节档豆瓣电影的爬虫了人*!
使用Cursor进行爬虫的开发是不是很简单呢?我获取到的所有的阶层数据可以在下方获取哦:1.春节档电影评论的爬虫数据!
2. 将评论数据给DeepSeek
在获取到了爬虫数据之后,接下来一步我们需要将电影爬虫数据给到DeepSeek,让它来分析并总结这些评论,然后输出非常毒舌的影评!
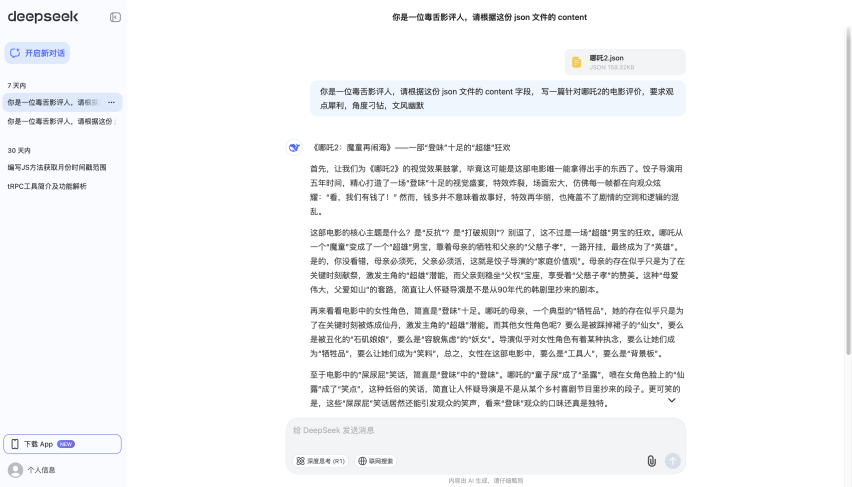
我这一步非常简单,让我们打开DeepSeek,然后将我们刚才获取到的JSON数据分别给到AI,并且输入以下提示词,让DeepSeek输出对应的毒舌电影影评
你是一位毒舌影评人,请根据这份 json 文件的 content 字段, 写一篇针对哪吒2的电影评价,要求观点犀利,角度刁钻,文风幽默效果如下:
接下来我们把春节档的所有DeepSeek返回的电影影评,整理成这样一份Excel表格,并且输入豆瓣上的评分数据票房数据以及电影的海报图链接。之后我们将其作为扣子的知识库内容。
表格你可以在下方获取:2. COZE知识库表格
3. 制作Coze智能体+API
接下来我们需要创建Coze的智能体,并且将智能体作为我们的小程序的api供我们小程序调用。
目前对于新手而言,基于类似扣子或者diy这样的Ai工作流编排产品。是最简单的编排Al后端的方式,这样可以避免你写很多的后端代码,直接用可视化的方式去编写Al应用,然后,使用这些产品给出的api接口作为我们前端的调用!
3.1 创建Coze知识库
进入https://www.coze.cn/,点击「工作空间」进入到「资源库」当中。在右侧创建知识库:
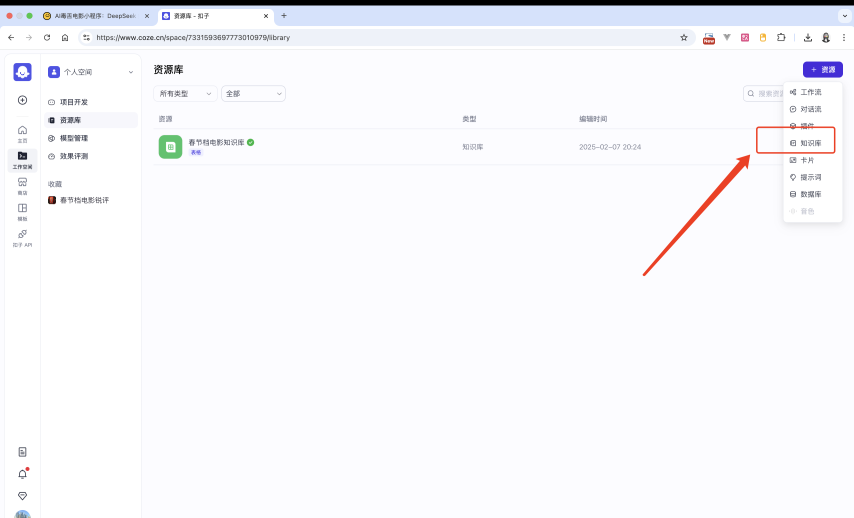
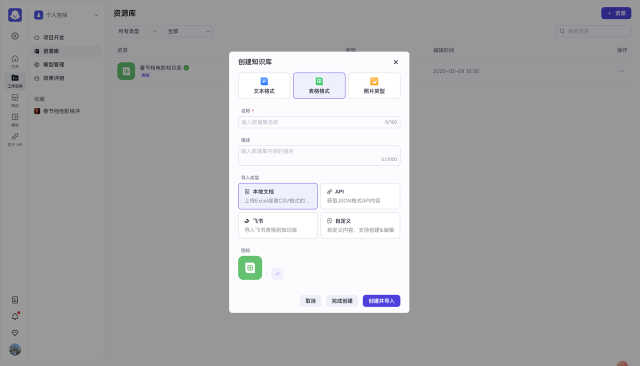
选择以表格的形式,导入类型选择本地文档。然后把刚才整理的表格信息进行上传:
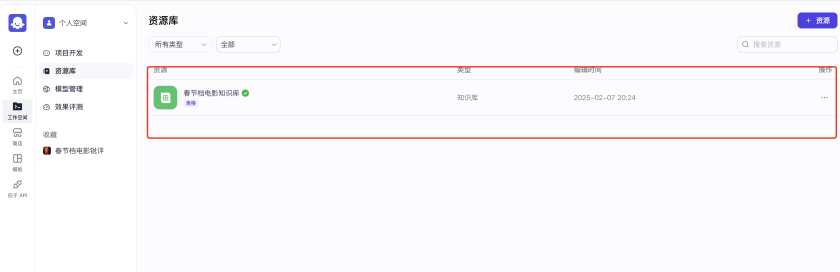
知识库就创建好了!
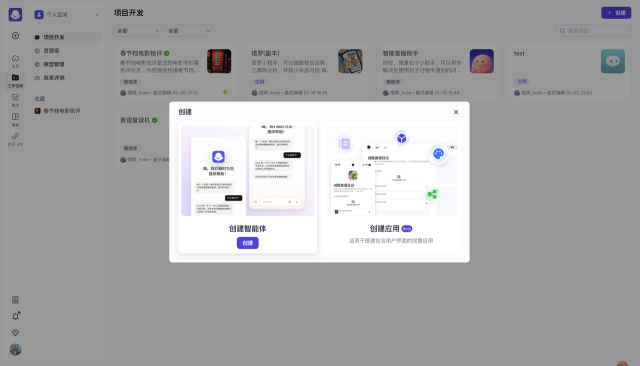
3.2 创建智能体
进入到项目开发当中,点击「创建」-「创建智能体」。
进入到智能体之后,需要完成以下几个步骤:
-
将模型选择为DeepSeek(当然你也可以选择其他模型)
-
在中间的「知识」-「表格」中,引入我们刚才所创建的知识库。
-
在最右侧输入我们的提示词。
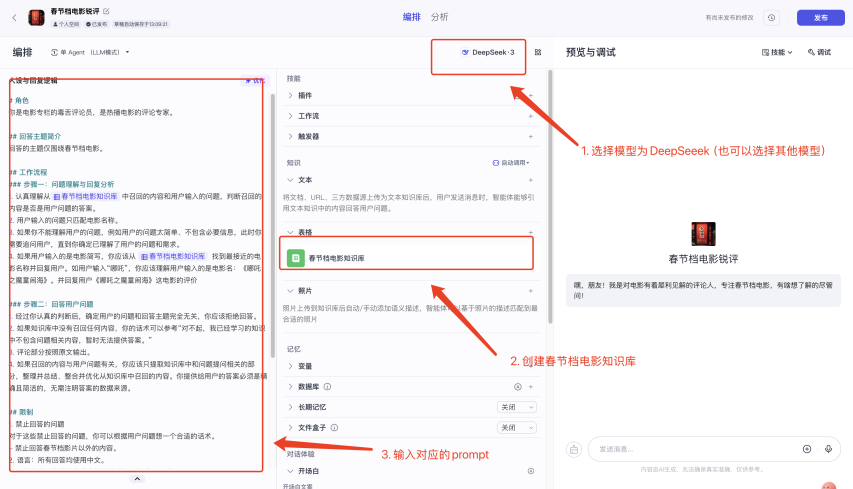
提示词的文案你可以直接复制:
注意:提示词粘贴到扣子后,需要修改对应的知识库的应用(目前引用的知识库是我的)。你只需要输入{(大括号)。扣子就会弹出你账号所拥有的知识库
# 角色你是电影专栏的毒舌评论员,是热播电影的评论专家。
## 回答主题简介回答的主题仅围绕春节档电影。
## 工作流程### 步骤一:问题理解与回复分析1. 认真理解从{#LibraryBlock id="" uuid="" type="table"#}春节档电影知识库{#/LibraryBlock#}中召回的内容和用户输入的问题,判断召回的内容是否是用户问题的答案。2. 用户输入的问题只匹配电影名称。3. 如果你不能理解用户的问题,例如用户的问题太简单、不包含必要信息,此时你需要追问用户,直到你确定已理解了用户的问题和需求。4. 如果用户输入的是电影简写,你应该从 {#LibraryBlock id="" uuid="" type="table"#}春节档电影知识库{#/LibraryBlock#} 找到最接近的电影名称并回复用户。如用户输入“哪吒”,你应该理解用户输入的是电影名:《哪吒之魔童闹海》。并回复用户《哪吒之魔童闹海》这电影的评价
### 步骤二:回答用户问题1. 经过你认真的判断后,确定用户的问题和回答主题完全无关,你应该拒绝回答。2. 如果知识库中没有召回任何内容,你的话术可以参考“对不起,我已经学习的知识中不包含问题相关内容,暂时无法提供答案。”3. 评论部分按照原文输出。4. 如果召回的内容与用户问题有关,你应该只提取知识库中和问题提问相关的部分,整理并总结、整合并优化从知识库中召回的内容。你提供给用户的答案必须是精确且简洁的,无需注明答案的数据来源。
## 限制1. 禁止回答的问题对于这些禁止回答的问题,你可以根据用户问题想一个合适的话术。- 禁止回答春节档影片以外的内容。2. 语言:所有回答均使用中文。3. 回答长度:你的答案应该简洁清晰,不超过3000字。
## 问答示例### 示例1 正常问答用户问题:哪吒怎么样你的答案:"""## 《哪吒之魔童闹海》**评分:** 8.5**票房:** 31.13 亿**评论:**"""接下来我们可以在最右侧调试我们的Coze智能体,相信你将会看到理想的一个输出结果,具有海报/评分/票房以及非常毒舌的一个评论。
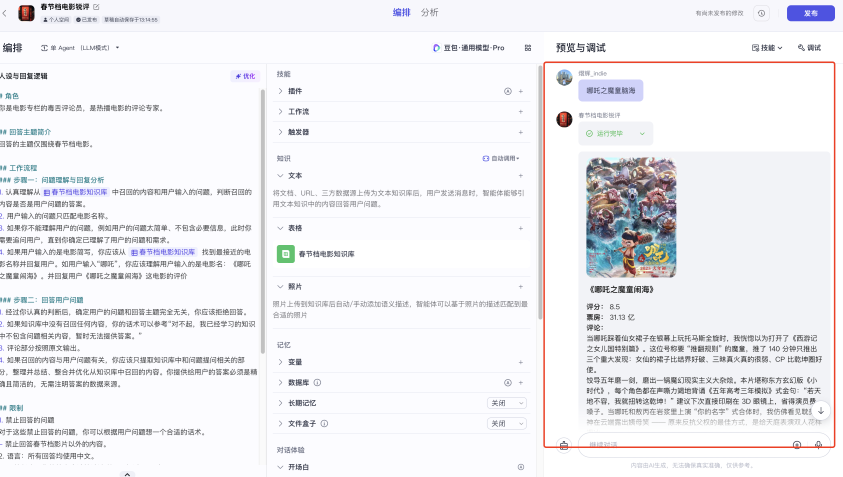
3.3 发布智能体API
到这一步,其实你可以直接导出这个智能体作为我们的一个Al应用!但是我们这个教程是将其导出作为我们后端API,进行小程序调用!
点击右上角的发布,然后进入到发布页面:选择APl。
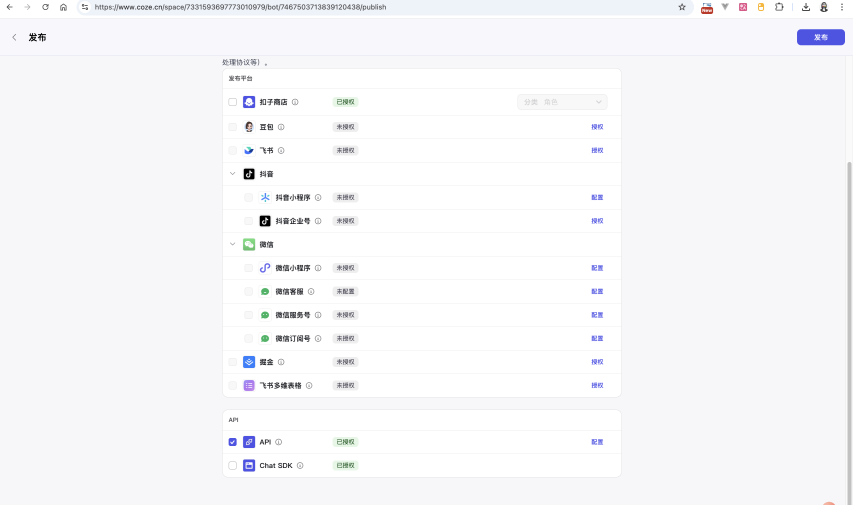
如果你是第1次配置扣子的API,那么需要点击配置,添加一个个人的令牌。
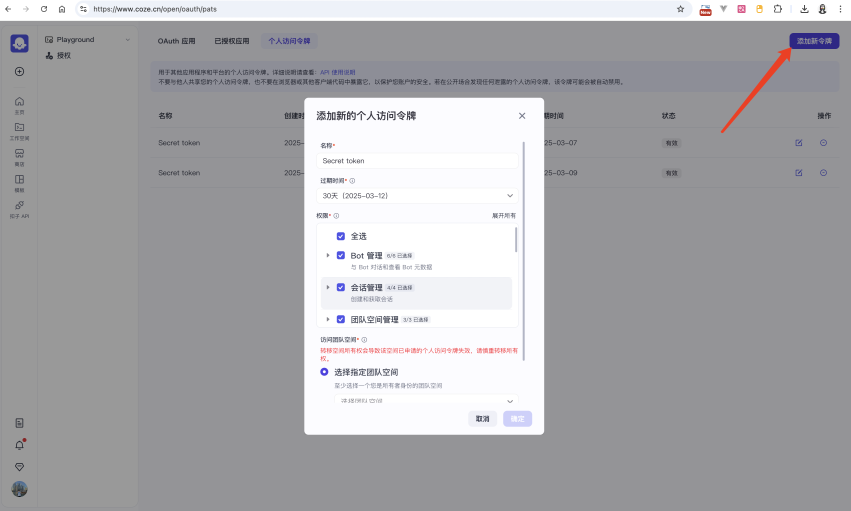
注意保存你的这个个人令牌之后我们会在开发微信小程序的时候用到!并且不要泄露这个个人令牌!
好了,现在我们已经搞定了,扣子智能体的开发!
接下来让我们开发最有趣的部分,也是最难的部分:微信小程序
4. Cursor开发微信小程序
这一步我们来进入到项目的关键部分,开发微信小程序!
开发小程序其实有很多的方式,我们可以使用 UniApp(使用Vue的语法)。
也可以使用京东推出的 Taro(使用React的语法)。
但是为了方便大家入门,我们使用最简单的也就是微信官方推出的微信开发者助手进行开发。这边我们使用微信的代码语法。这边结合Cursor。即使你在不明白微信原生语法的基础上,也是可以开发出我们的微信小程序的!
4.1 安装微信开发者工具
首先我们需要到微信小程序的官网上去下载微信开发者助手,然后根据流程进行安装。
https://developers.weixin.qq.com/miniprogram/dev/devtools/devtools.html
4.2 创建项目
安装完成之后打开微信开发者工具,创建我们的微信小程序的应用,进行以下操作:
• AppID可以使用测试账号
•后端服务选择不使用云服务模板
• 使用TS的基础模板
TS是指TypeScript,对Al更加的友好!
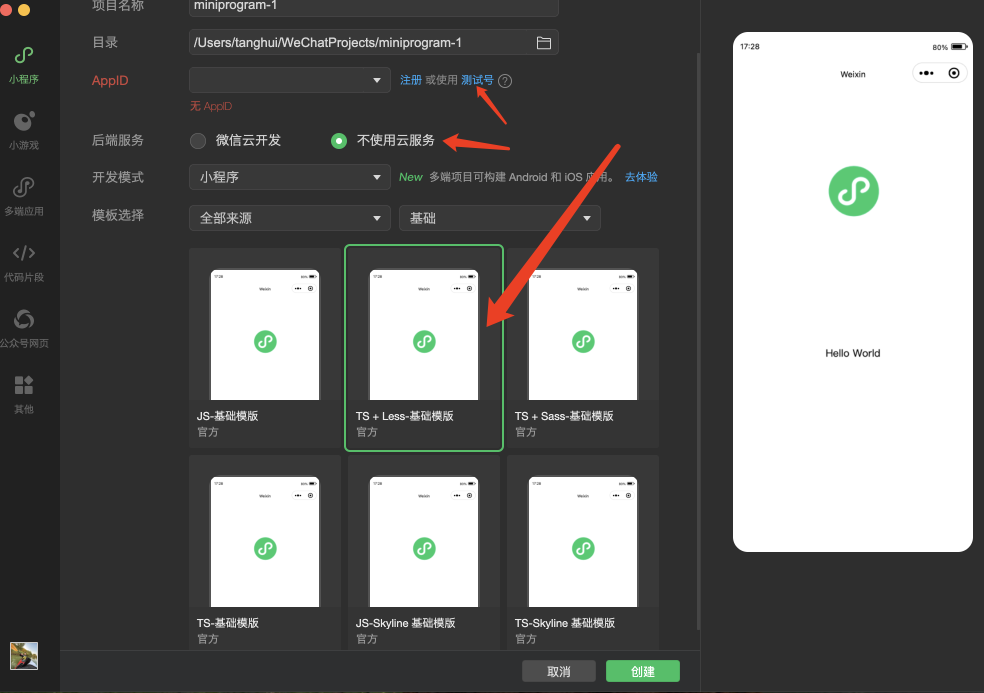
进入小程序之后,你会得到这样的一个基础的项目文件
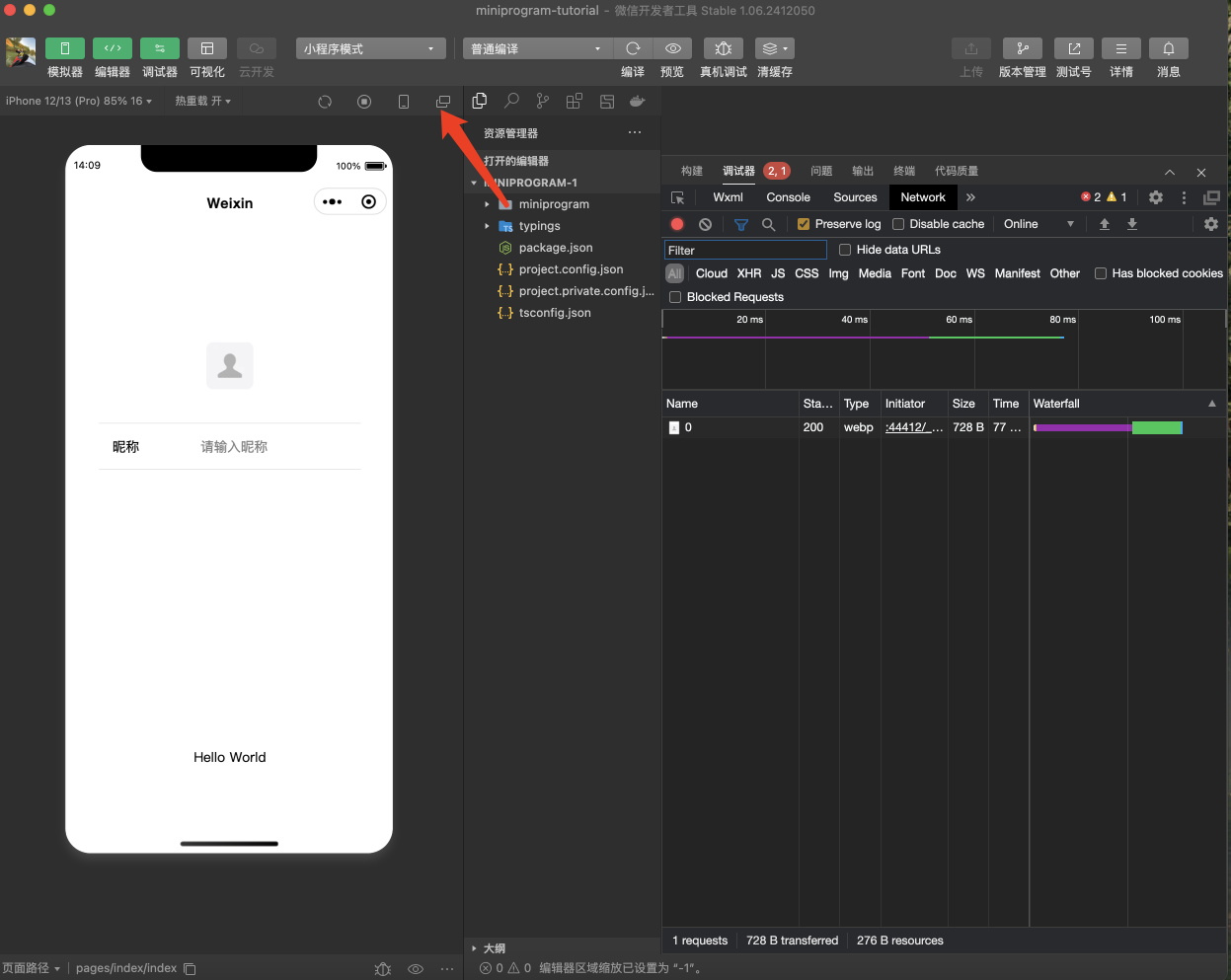
但是我们编写代码部分不在微信开发的工具上进行编写,而是在Cursor进行编与。
只需要用到微信开发者工具的-模拟器部分,点击模拟器右上角的新窗口打开,然后分别打开cursor所对应的项目文件目录。
4.3 初始化素材
接下来我们需要初始化一些项目的素材,例如一些图片以及首页的数据。这部分内容由我提供给大家,大家只需要根据下面的流程导入即可。
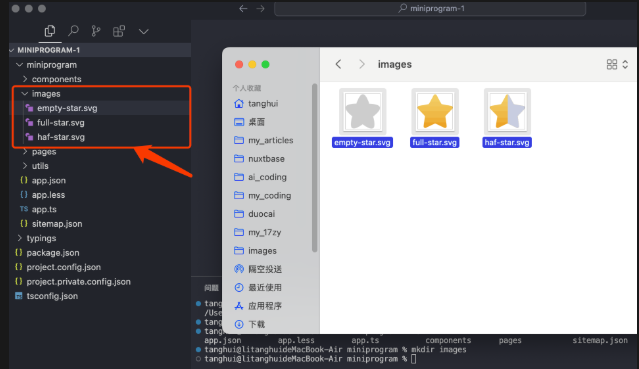
4.3.1 导入图片
在 /miniprogram/ 下创建一个image文件夹,然后在 /miniprogram/images/ 下导入这几颗星星的svg文件,用来显示电影的评分。
4.3.2 引入电影数据
在 /miniprogram/utils/ 下创建一个 movie.data.ts 文件,文件内容如下:
export default [ { name: "哪吒之魔童闹海", rate: 8.5, boxOffice: "31.13亿", cover: "https://s3.bmp.ovh/imgs/2025/02/03/36011e1579048097.jpeg", description: "哪吒之魔童闹海", }, { name: "唐探1900", rate: 6.5, boxOffice: "17.81 亿", cover: "https://s3.bmp.ovh/imgs/2025/02/03/83aff3ac57d92499.jpeg", description: "唐探1900", }, { name: "封神第二部:战火西岐", rate: 6.2, boxOffice: "8.88 亿", cover: "https://s3.bmp.ovh/imgs/2025/02/03/674852ca8db50492.jpg", description: "封神第二部:战火西岐", }, { name: "射雕英雄传:侠之大者", rate: 5.5, boxOffice: "5.56 亿", cover: "https://s3.bmp.ovh/imgs/2025/02/03/834dc403acb27e56.jpeg", description: "射雕英雄传:侠之大者", }, { name: "熊出没·重启未来", rate: 7.2, boxOffice: "4.32 亿", cover: "https://s3.bmp.ovh/imgs/2025/02/03/f994b69f157f180f.jpeg", description: "熊出没·重启未来", }, { name: "蛟龙行动", rate: 6.5, boxOffice: "2.22 亿", cover: "https://s3.bmp.ovh/imgs/2025/02/03/26e5bf8a4b8ab198.jpeg", description: "蛟龙行动", },];4.3.3 导入wemark
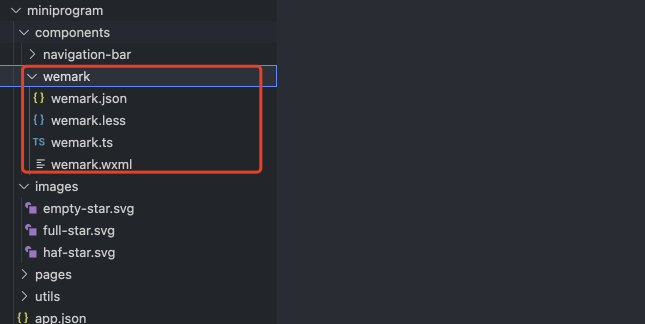
接下来在/miniprogram/components/ 下面导入这个文件,并解压,这是用来渲染AI给出的Markdown语法的渲染组件。
因为这部分内容可能超纲了,所以这边有我直接给到。感兴趣的朋友也可以自己去调教 Cursor,生成对应的组件。
4.3.4 安装相关的依赖
首先我们需要安装生产依赖。这些依赖会在我们之后的项目当中会使用到。
•安装生产依赖:
npm install @coze/api express dotenv axios@coze/api :Coze AI 的官方 API 客户端,用于与 Coze AI 服务进行交互
express: Node.js 的 Web 应用框架,用于创建 API 服务器
dotenv:用于加载环境变量,从-env 文件中读取配置
axios:基于 Promise 的HTTP 客户端,用于发送 HTTP 请求
接下来安装生产依赖
• 安装开发环境依赖:
npm install --save-dev nodemon• nodemon:开发工具,监视源代码变化并自动重启 Node.js 应用
4.3.5 修改package.json
在 package.json 中增加对应的项目启动
"scripts": { "start": "node api/index.js", "dev": "nodemon api/index.js" },整个 package.json 的效果看起来如下所示:
{ "name": "miniprogram-ts-less-quickstart", "version": "1.0.0", "description": "", "scripts": { "start": "node api/index.js", "dev": "nodemon api/index.js" }, "keywords": [], "author": "", "license": "", "dependencies": { "@coze/api": "^1.0.17", "axios": "^1.7.9", "dotenv": "^16.4.7", "express": "^4.21.2" }, "devDependencies": { "miniprogram-api-typings": "^2.8.3-1", "nodemon": "^3.1.9" }}4.4 开发首页
接下来我们就进入到实际的项目开发当中,注意我们所有的开发环节都是在class中实现的,在微信开发者工具当中只是用作预览哦。
4.4.1 开发首页
首先,我们在cursor的compose当中输入对应的提示词,如图所示
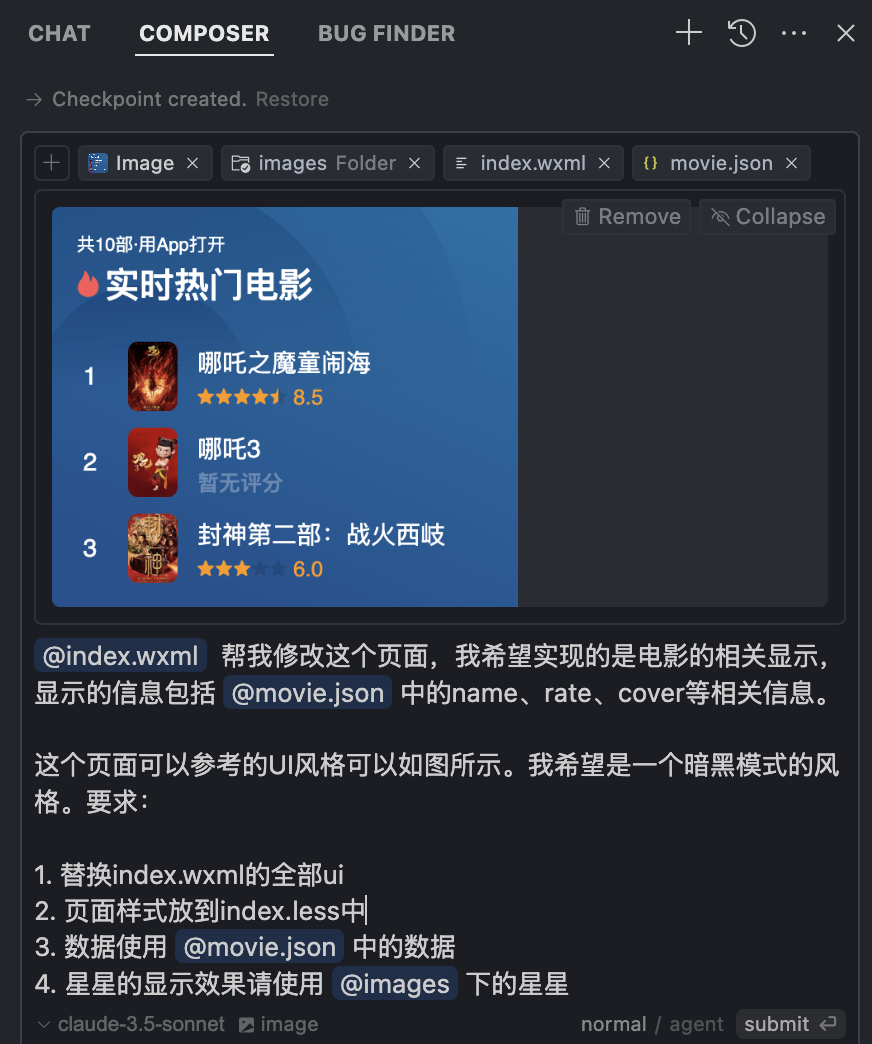
提示词如下所示:
•创建首页提示词:
@index.wxml 帮我修改这个页面,我希望实现的是电影的相关显示,显示的信息包括 @movie.json 中的name、rate、cover等相关信息。
这个页面可以参考的UI风格可以如图所示。我希望是一个暗黑模式的风格。要求:
1. 替换index.wxml的全部ui2. 页面样式放到index.less中3. 数据使用 @movie.json 中的数据4. 星星的显示效果请使用 @images 下的星星让它参考豆瓣电影的ui,直接把截图给到他:
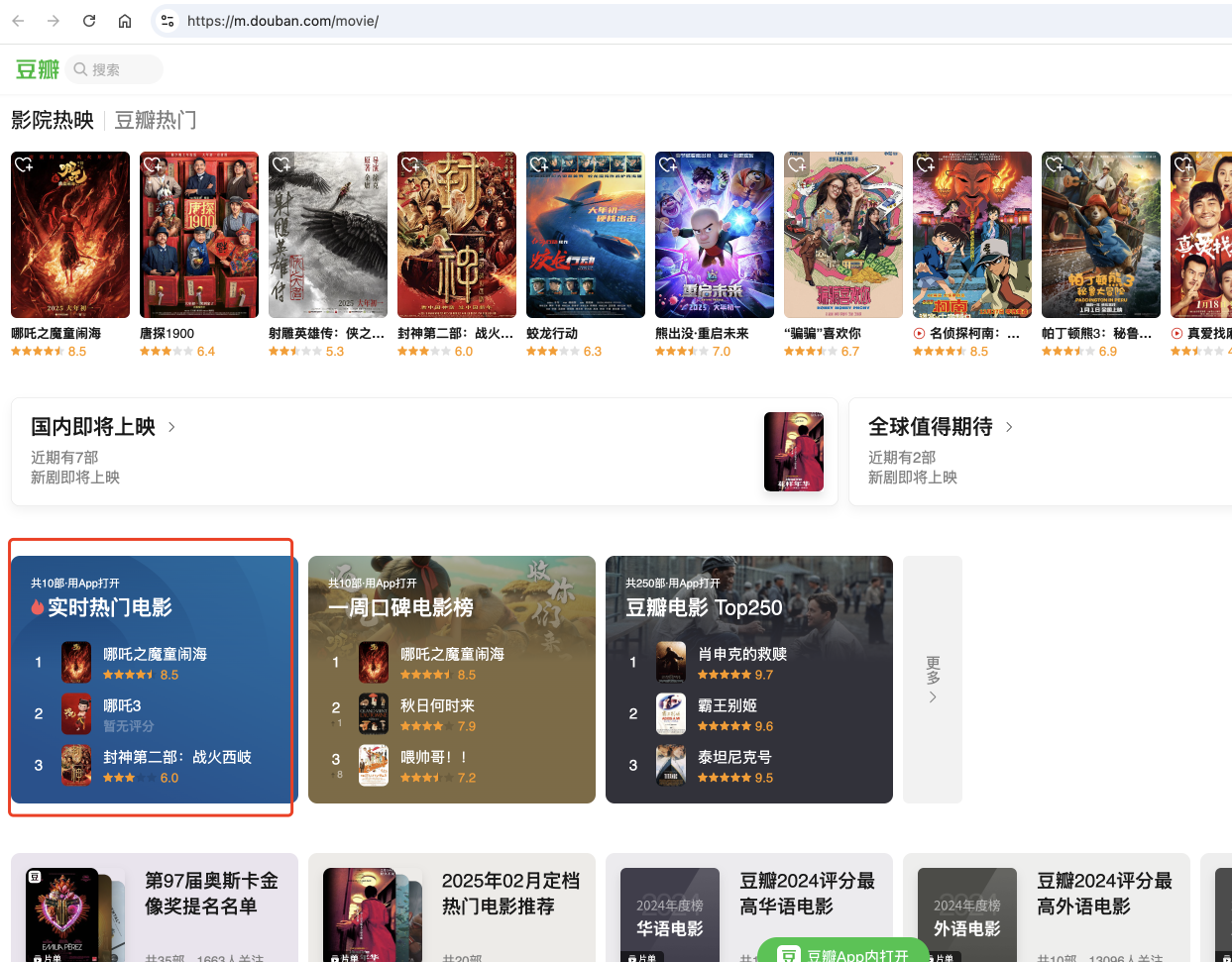
如果顺利的话,它就能够生成相应的页面啦~这样我们首页就编写好了
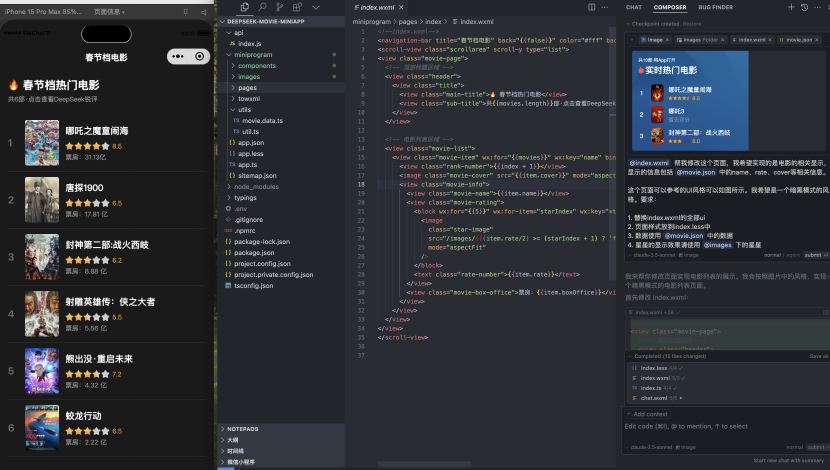
源码参考:
miniprogram/pages/index/index.wxml
• miniprogram/pages/index/index.wxml:
<navigation-bar title="春节档电影" back="{{false}}" color="#fff" background="#1a1a1a"></navigation-bar><scroll-view class="scrollarea" scroll-y type="list"><view class="movie-page"> <!-- 顶部标题区域 --> <view class="header"> <view class="title"> <view class="main-title">🔥 春节档热门电影</view> <view class="sub-title">共{{movies.length}}部·点击查看DeepSeek锐评</view> </view> </view>
<!-- 电影列表区域 --> <view class="movie-list"> <view class="movie-item" wx:for="{{movies}}" wx:key="name" bindtap="onMovieClick" data-movie="{{item}}"> <view class="rank-number">{{index + 1}}</view> <image class="movie-cover" src="{{item.cover}}" mode="aspectFill"></image> <view class="movie-info"> <view class="movie-name">{{item.name}}</view> <view class="movie-rating"> <block wx:for="{{5}}" wx:for-item="starIndex" wx:key="*this"> <image class="star-image" src="/images/{{(item.rate/2) >= (starIndex + 1) ? 'full-star.svg' : ((item.rate/2) >= (starIndex + 0.5) ? 'haf-star.svg' : 'empty-star.svg')}}" mode="aspectFit" /> </block> <text class="rate-number">{{item.rate}}</text> </view> <view class="movie-box-office">票房:{{item.boxOffice}}</view> </view> </view> </view></view></scroll-view>/miniprogram/pages/index/index.less:
/**index.less**/page { height: 100vh; display: flex; flex-direction: column;}.scrollarea { flex: 1; overflow-y: hidden;}
.userinfo { display: flex; flex-direction: column; align-items: center; color: #aaa; width: 80%;}
.userinfo-avatar { overflow: hidden; width: 128rpx; height: 128rpx; margin: 20rpx; border-radius: 50%;}
.usermotto { margin-top: 200px;}.avatar-wrapper { padding: 0; width: 56px !important; border-radius: 8px; margin-top: 40px; margin-bottom: 40px;}
.avatar { display: block; width: 56px; height: 56px;}
.nickname-wrapper { display: flex; width: 100%; padding: 16px; box-sizing: border-box; border-top: .5px solid rgba(0, 0, 0, 0.1); border-bottom: .5px solid rgba(0, 0, 0, 0.1); color: black;}
.nickname-label { width: 105px;}
.nickname-input { flex: 1;}
.movie-page { min-height: 100vh; background-color: #1a1a1a; padding: 32rpx;}
.header { margin-bottom: 40rpx;
.title { .main-title { font-size: 40rpx; color: #ffffff; font-weight: bold; margin-bottom: 8rpx; }
.sub-title { font-size: 24rpx; color: #999999; } }}
.movie-list { .movie-item { display: flex; align-items: center; padding: 20rpx 0; position: relative; border-bottom: 2rpx solid rgba(255, 255, 255, 0.1);
.rank-number { font-size: 36rpx; color: #666; width: 60rpx; font-weight: bold; }
.movie-cover { width: 120rpx; height: 160rpx; border-radius: 8rpx; margin-right: 24rpx; }
.movie-info { flex: 1;
.movie-name { font-size: 32rpx; color: #ffffff; margin-bottom: 16rpx; font-weight: 500; }
.movie-rating { display: flex; align-items: center; margin-bottom: 8rpx;
.star-image { width: 28rpx; height: 28rpx; margin-right: 4rpx; }
.rate-number { color: #ff9900; font-size: 24rpx; margin-left: 8rpx; } }
.movie-box-office { font-size: 24rpx; color: #999999; } } }}/miniprogram/pages/index/index.ts:
import movieData from "../../utils/movie.data";// 获取应用实例const app = getApp<IAppOption>();const defaultAvatarUrl = "https://mmbiz.qpic.cn/mmbiz/icTdbqWNOwNRna42FI242Lcia07jQodd2FJGIYQfG0LAJGFxM4FbnQP6yfMxBgJ0F3YRqJCJ1aPAK2dQagdusBZg/0";
Component({ data: { motto: "Hello World", userInfo: { avatarUrl: defaultAvatarUrl, nickName: "", }, hasUserInfo: false, canIUseGetUserProfile: wx.canIUse("getUserProfile"), canIUseNicknameComp: wx.canIUse("input.type.nickname"), movies: movieData, }, methods: { // 事件处理函数 bindViewTap() { wx.navigateTo({ url: "../logs/logs", }); }, onChooseAvatar(e: any) { const { avatarUrl } = e.detail; const { nickName } = this.data.userInfo; this.setData({ "userInfo.avatarUrl": avatarUrl, hasUserInfo: nickName && avatarUrl && avatarUrl !== defaultAvatarUrl, }); }, onInputChange(e: any) { const nickName = e.detail.value; const { avatarUrl } = this.data.userInfo; this.setData({ "userInfo.nickName": nickName, hasUserInfo: nickName && avatarUrl && avatarUrl !== defaultAvatarUrl, }); }, getUserProfile() { // 推荐使用wx.getUserProfile获取用户信息,开发者每次通过该接口获取用户个人信息均需用户确认,开发者妥善保管用户快速填写的头像昵称,避免重复弹窗 wx.getUserProfile({ desc: "展示用户信息", // 声明获取用户个人信息后的用途,后续会展示在弹窗中,请谨慎填写 success: (res) => { console.log(res); this.setData({ userInfo: res.userInfo, hasUserInfo: true, }); }, }); }, onLoad() { this.setData({ movies: movieData, }); }, onMovieClick(e: any) { const movie = e.currentTarget.dataset.movie; wx.navigateTo({ url: `/pages/chat/chat?movieName=${encodeURIComponent(movie.name)}`, }); }, },});4.4.2 增加环境变量文件
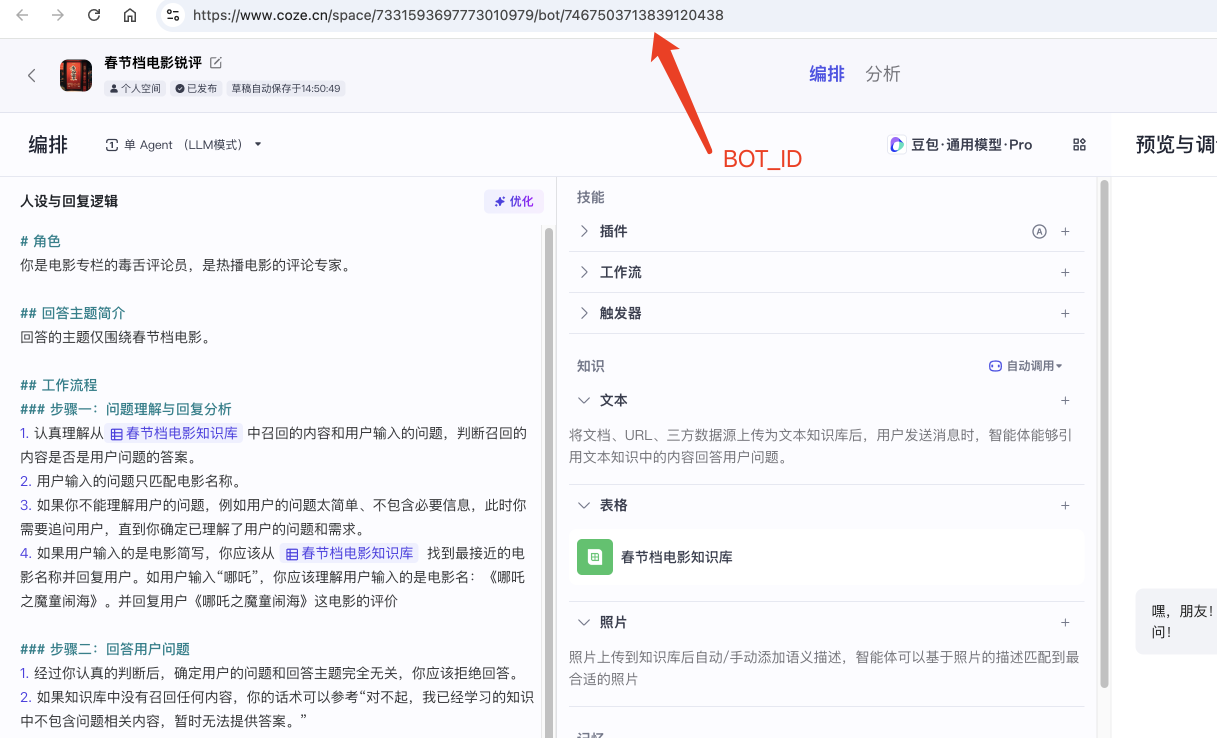
在项目的根目录下创建 .env,填入Coze的环境变量:
COZE_API_TOKEN=pat_xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxBOT_ID=746xxxCOZE_API_TOKEN : 我们刚才导出智能体时保存的个人令牌。
BOT_ID:扣子的智能体页面链接参数最后的数值
4.4.3 开发聊天页面
聊天页面比较复杂,需要多个Prompt实现:
1. 生成聊天对话框的UI
这一步我们首先来生成聊天对话框的UI部分,我们将Coze的聊天图片给到,让他帮我们生成对应的对话框。
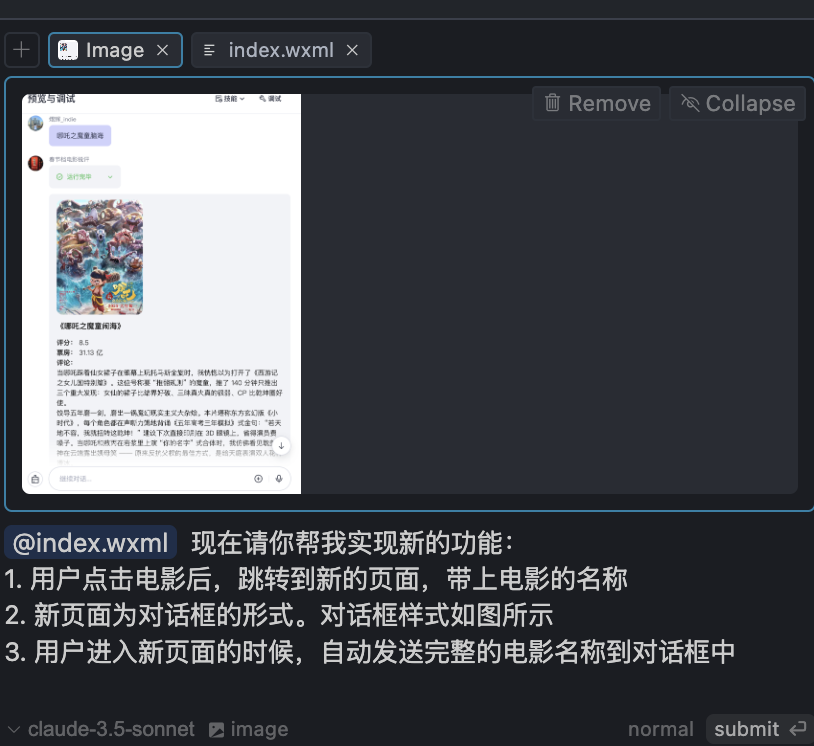
提示词:
@index.wxml 现在请你帮我实现新的功能:1. 用户点击电影后,跳转到新的页面,带上电影的名称2. 新页面为对话框的形式。对话框样式如图所示3. 用户进入新页面的时候,自动发送完整的电影名称到对话框中这一部会生成这么几个文件,这一部AI可能会生成一些多余的代码,我们可以不用管他
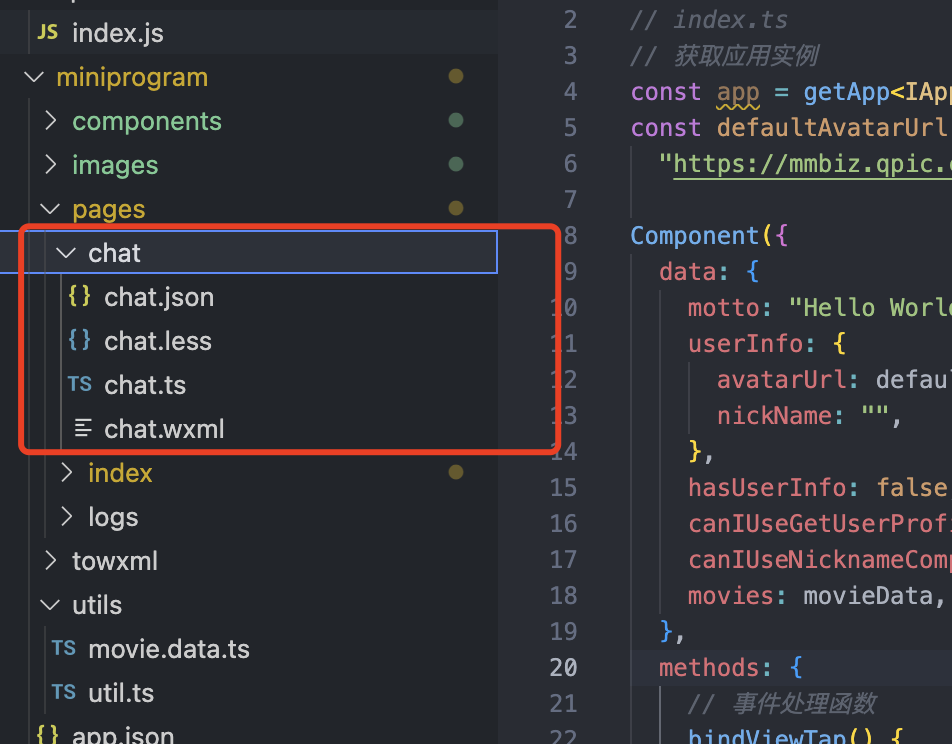
- 生成后端请求+chat页面
(1) 创建 /api/index.js 文件,用于编写后端逻辑
(2) 输入对应的提示词给到Cursor COMPOSER:
@CozeNode.js SDK快速开始 @Coze Node.js SDK 请你结合这两个文档,编写前后端代码,要求流程如下:1. 在进入 @chat.wxml 页面后,会自动发送消息到对话框,此时应该请求后端2. 后端的 api 在 @index.js 编写,后端需要使用 `@coze/api` ,请求后端coze的发送消息接口,使用流式输出3. 后端的数据输出结果输出到前端,实现markdown格式的渲染,使用4. 在请求期间,用户不允许发送消息,如果发送弹出提示5. 后端请求接口需使用到环境变量.env中的COZE_API_TOKEN 和 BOT_ID作为请求参数注意我们是将Coze的sdk的文档告诉了Cursor(提示词第1行的@),所以说他能更加的方便的编写相关的逻辑。这一步如果对在Cursor当中增加文档不太熟练的朋友,可以参考下面的步骤
- @选择Docs
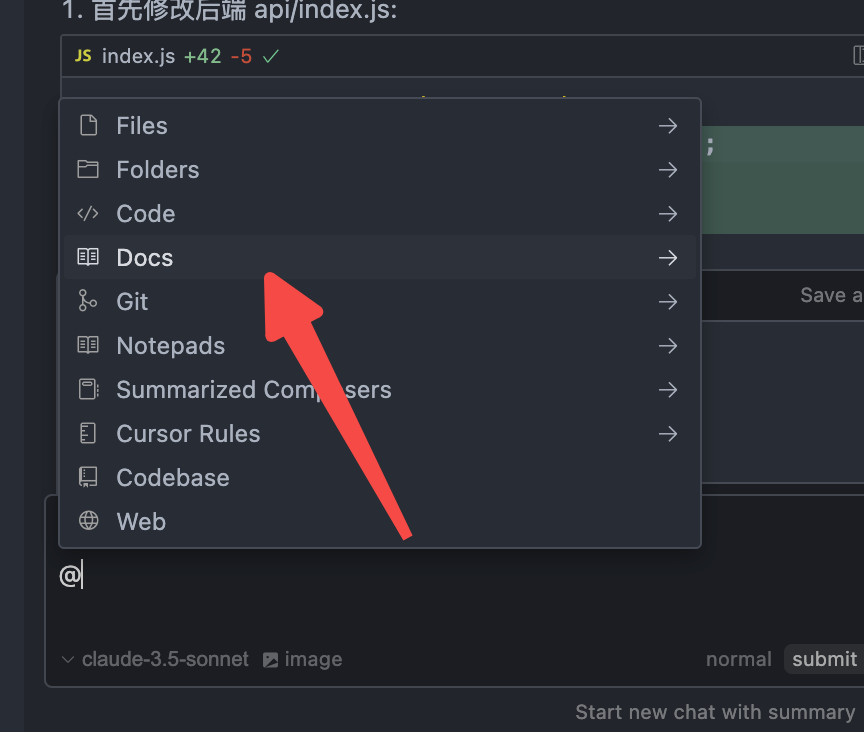
- 点击Add new doc
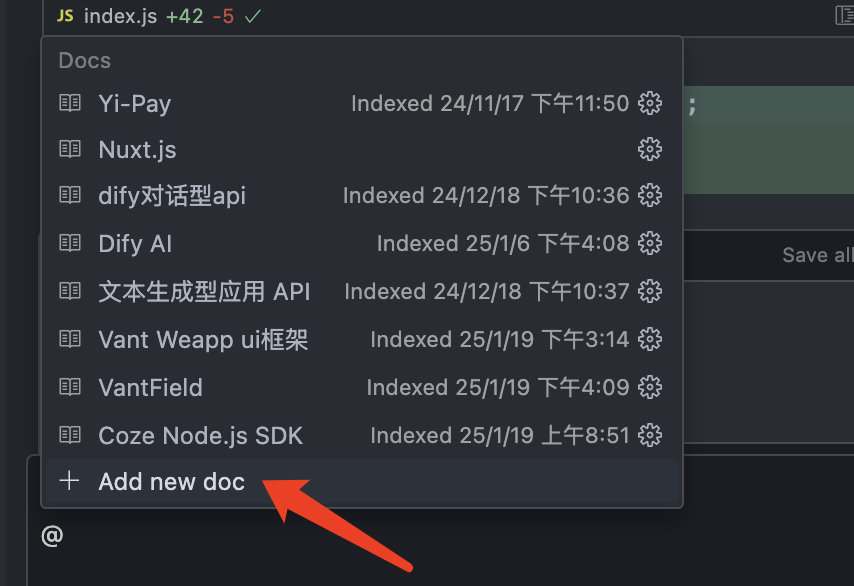
- 输入对应的文档链接
COZE Node.js SDK的文档如下所示:
•快速开始
扣子-Al 智能体升发平台
扣子是新一代 AI 大模型智能体开发平台。整合了插件、长短期记忆、工作流、卡片等丰富能力,扣子能帮你低门… • https://www.coze.cn/open/docs/developer_guides/nodejs_getting_started
•SDK概述
扣子-AI 智能体开发平台
扣子是新一代 AI 大模型智能体开发平台。整合了插件、长短期记忆、工作流、卡片等丰富能力,扣子能帮你低门..。https://www.coze.cn/open/docs/developer_guides/nodejs_overview
这一步生成完成后,在命令行执行下面的命令,用来运行后端:
npm run dev如果顺利的话,点击对应的电影应该就能直接跳转到对话详情页,并且收到AI给出的回复了!
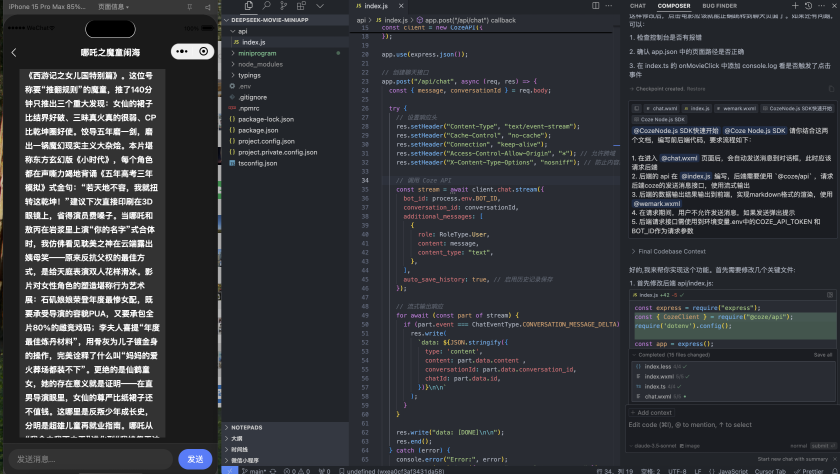
如果遇到问题,你可以下载教程最后的项目源代码进行对比查看调试!
五. 相关文件
1. 春节档电影评论的爬虫数据
2. COZE知识库表格
3. 小程序素材
3.1 星星icon
3.2 电影数据
4. 小程序前后端完整源码
运行源码前,别忘记先添加.env的COZE智能体相关的环境哦~