Codex入门完整版:制作一个英语背单词应用
/ 28 min read
1. 项目讲解
本期课程,是我们Codex入门的实战课。我们会详细介绍Codex的基础使用技巧,并且通过2个实战案例来巩固Codex的使用,如果你有使用过Claude Code,那么Codex的使用还是有一些不同的。
简单的说,就是你的提示词所对应的任务的颗粒度要尽可能的小一点,这样它会带来更好的效果。
我们会使用Github上一个英语单词的仓库数据,来制作一个背单词的H5应用,以及配套的管理后台。
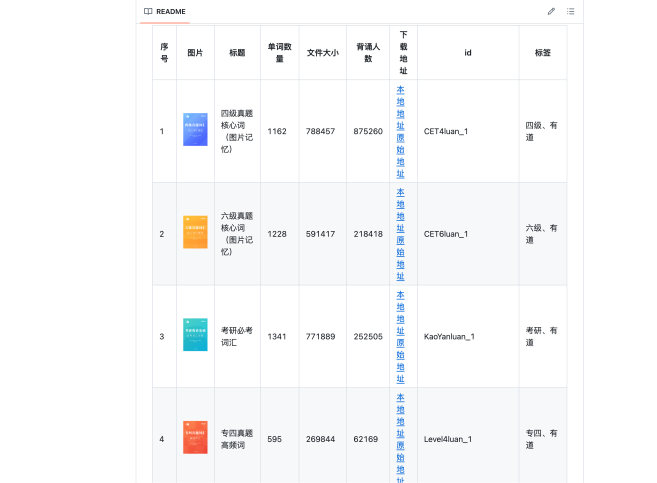
单词书管理后台,我们会使用到Codex CLI的开发方式。
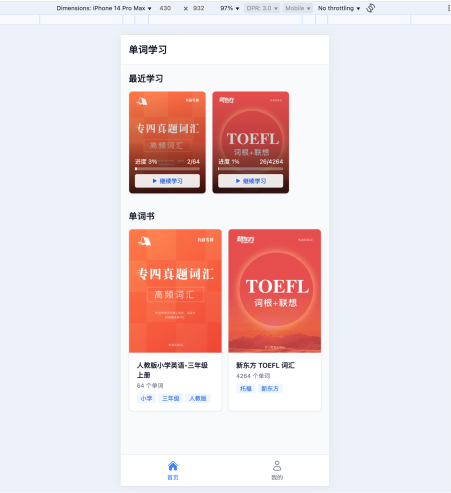
至于背单词H5应用的开发,我们会使用Cursor + Codex的插件实现。
通过基于概念讲解+不同使用方式的实战学习,来确保你完全掌握Codex的使用。
2. Codex入门
2.1 安装

Codex的使用方式有3种:
• Codex CLI:使用类似Claude Code的CLI运行
• Codex IDE:使用扩展的方式,在你熟悉的IDE中使用
• Codex Cloud:使用Codex的云端环境显示
我们主要讲解前面两种,也就是使用Codex CLI 和 Codex IDE。
2.1.1 使用Codex CLI
想要使用Codex CLI很方便,只需要在你的终端中输入以下命令就好。
npm install -g @openai/codex如果遇到权限不足,在前面添加上 sudo 命令, 既 sudo npm install -g @openai/codex 安装。
之后在命令行中输入 codex,就会要求你进行登录方式。建议使用第一种基于ChatGPT 账号实现登陆。Plus/Pro/Team Plans都可以免费使用Codex CLI。
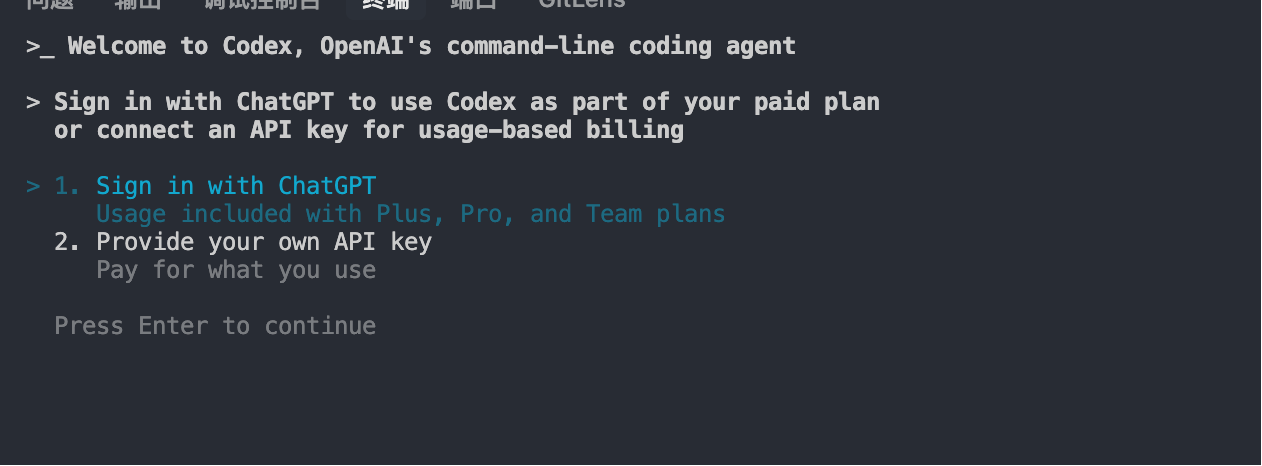
回车进入到这一步的的时候,建议选择1:Codex 在该目录下运行的时候,不用我一一授权,这样会很让人很烦。
注意目录位置
一定要注意codex打开的目录位置,要在项目的根目录上使用。不要直接打开 Terminal后开始使用,这样会在你的个人根目录,是不对的!
2.1.2 使用Codex插件
Codex也支持在CLI中使用,直接在你熟悉的IDE中搜索”Codex“或者“OpenAI”,找到 Codex安装就好。
然后按下 Command +Shift +P,输入Codex就可以看到侧边栏中有Codex的对话框了。接下来我们就可以使用Codex了。
Codex的使用和Cursor很像,我相信你之前用过Cursor,就能无痛掌握。你可以切换模式,建议使用 Agent(full access)。如果你是Plus会员,建议使用gpt5-high的模型。
2.2 Codex CLI基础命令
2.2.1非交互命令
像Claude Code和Codex这类CLI工具,都会提供交互式命令和交互式命令两种方法。非交互式命令只会一次性执行命令,然后退出。
CLI Codex的非交互式命令,相对于Claude Code来说,目前要少很多,也基本不会使用到,我们最常用的还是使用 codex 后进入到交互式命令窗口。
你可以运行 codex —help,查看所有的非交互式命令。
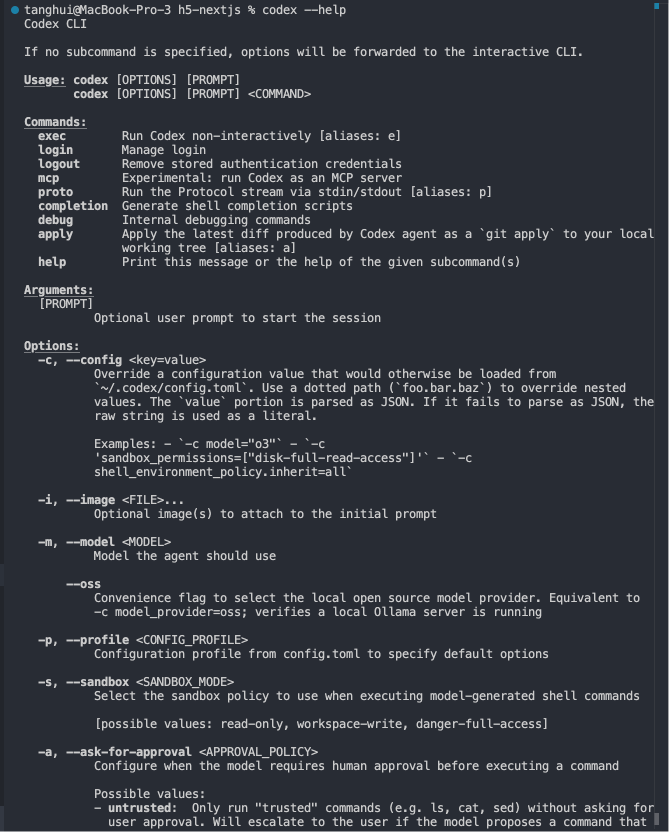
2.2.2 交互式命令
这部分我们来学习Codex CLI的交互式命令,Codex目前截止2025年9月10日,功能和命令要比Claude Code少很多,学习成本会少很多。你可以输入/后,就可以查看Codex 目前支持的所有交互式命令。
1. 常用命令最常用的包括:
。/model:选择模型,默认或者使用gpt5 high。
。/approval:选择codex的授权方式
。/status :查看当前任务的配置
。/new:开启一个新对话,可以在项目的功能点之间没有太多关联的时候开启新对话,节省token使用
。/init:创建 AGENTS.md 文件,类似Claude Code的 CALUDE.md 包含你项目的通用规则和约束
。/mcp:查看我们配置的MCP
。compact:压缩对话上下文,以避免达到最大上下文长度
2.@和图片
•使用@,可以唤起文件的提示功能。这很重要,指定文件在Codex中相比较ClaudeCode更加重要
• 粘贴图片使用使用ctrl +V,而不是MacOS中常用的 Command +V,这点很重要
3. 如何使用MCP?
Codex中配置MGP和其他都不一样,是使用TOML的配置文件,就是使用**.toml**结尾的配置文件类型。
这个配置文件目前在 ~/.codex 目录下,你可以在命令行中输入以下命令,打开该文件实现配置。
cursor ~/.codex/config.toml也可以在Codex的插件中,点击右上角小齿轮,点击【MCP】- 【Open config.toml】 实现配置。
以我们经常使用的Context7为例,添加以下配置信息:
config.toml:
[mcp_servers.context7]args = ["-y", "@upstash/context7-mcp", "--api-key", "YOUR_API_KEY"]command = "npx"这个配置文件很好理解,虽然你第一次可能比较陌生,但是它的可读性相比较JSON,其实是要好理解很多的。
2.3 Codex vs Claude Code
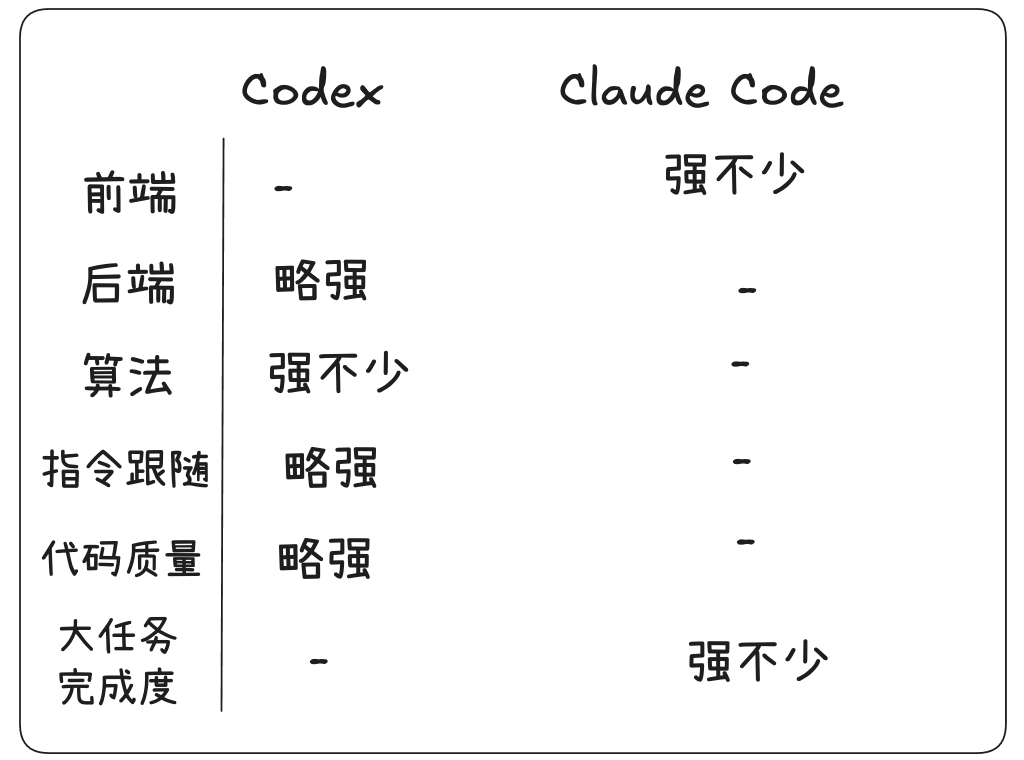
在高强度使用Codex和Claude Code, 这两者给我的实际使用体验如上图。

所以,如果你是一名纯编程小白,我个人认为现阶段还是Claude Code更加适合你
2.4 AGENTS.md
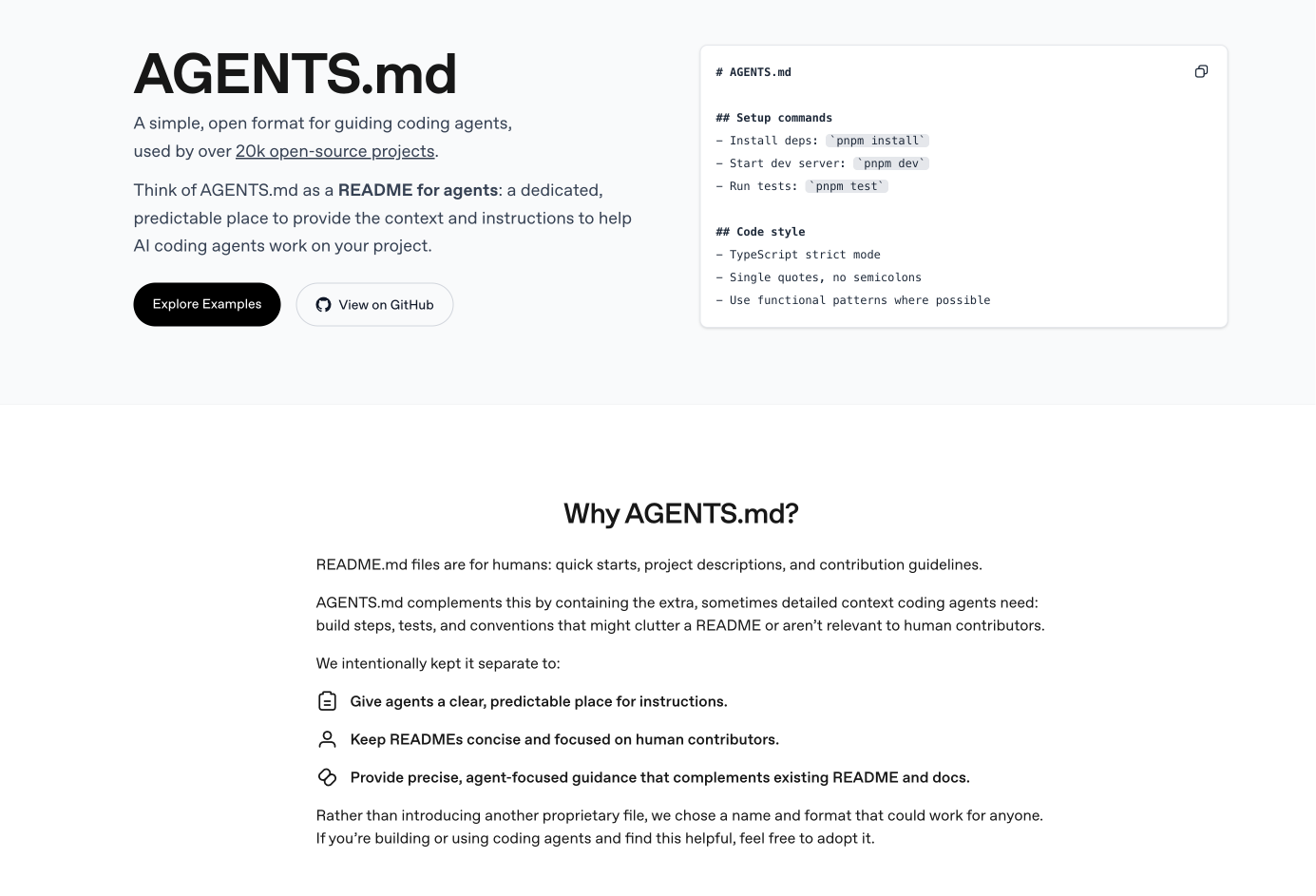
最后来讲一下AGENTS.md,这个是ChatGPT前头来给多个AI工具使用的一个文件,包括 Codex, Cursor, Kiro, Gemini CLI等.

AGENTS.md的内容没有固定的格式,你可以包含:
• Project overview 项目概述
• Build and test commands 构建和测试命令
• Code style guidelines 代码风格指南
• Testing instructions 测试说明
• Security considerations 安全注意事项
• deployment steps 部署步骤
你可以使用/init命令生 AGENTS.md,但是目前/init 命令生成的该文档会过于简单,我建议大家自行维护,或者使用我的提示词实现:
请你用中文重写AGENTS.md,要求实现:1. 项目概述2. 项目如何安装(包括环境变量)、运行、构建命令3. 项目前后端目录结构,页面路由、项目API接口4. 项目重要的技术栈和依赖说明5. 需要npm执行的,全部替换成pnpm3. Codex实战:单词书管理后台
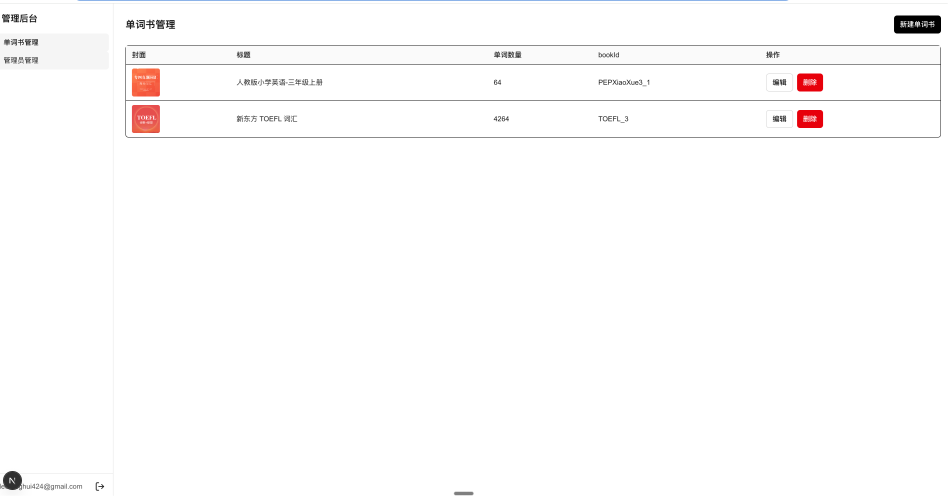
首先,我们来完成管理后台的一个开发。管理后台比较简单,只是实现一个单词书管理和管理员管理。
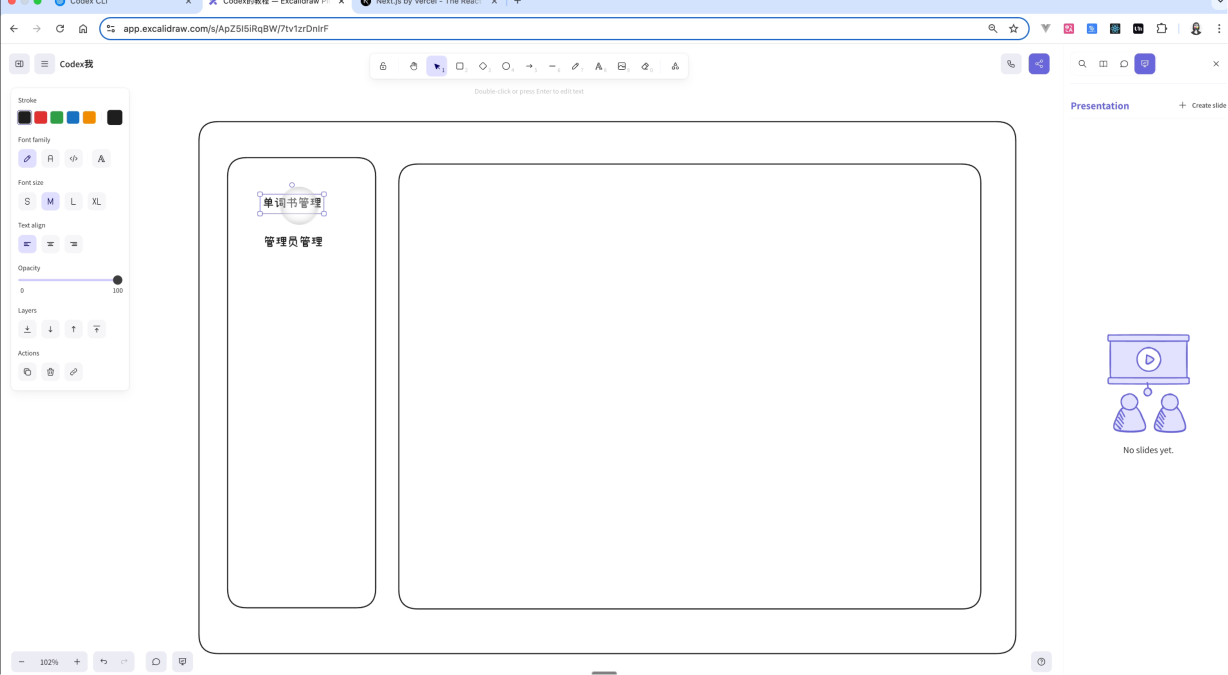
然后这一次的登录注册功能和之前有点不太一样。我们希望,如果第一次打开项目的时候,实现系统管理员的注册。之后是通过系统管理员给其他管理员分配权限的方式,也就不再提供注册功能。
这个是一些常规的后台的注册方式,这一次我们来通过Codex实现它。
3.1 初始化项目

我们使用 Nexer.js 框架的最基础的模板来开始进入开发。进入Next.js 的官网,输入下面的命令来完成新项目的搭建。
npx create-next-app@latest项目名称可命名为admin-nextjs,其余选项部分,没有特殊的需求,一路回车就好。
用Cursor打开打开项目,输入 pnpm run dev 完成项目的一个启动。
之后再先打开一个终端,在终端中输入 codex 来进入到 codex 的CLl。
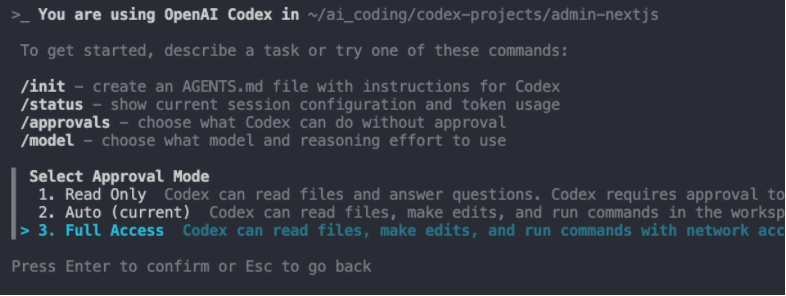
进入CLI之后:输入**/approvals**,调整成为Full Access

输入 model, 选择 gpt-5 high (可选)。
3.2 管理后台UI开发
提示词:
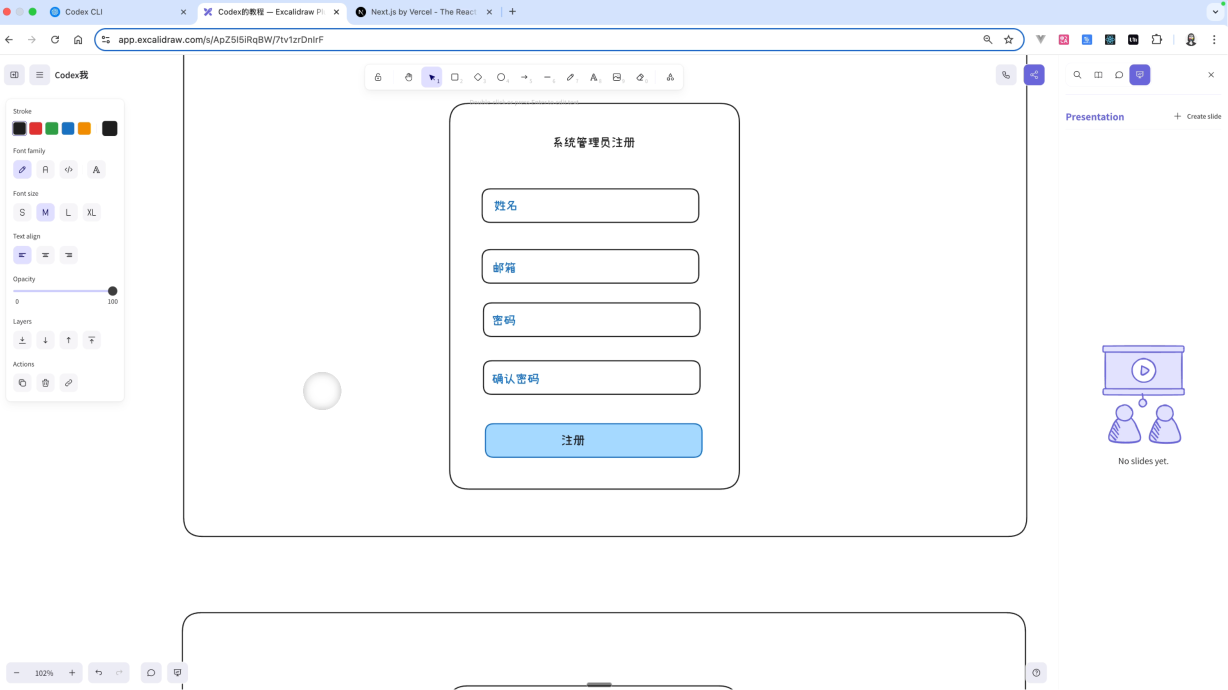
请你帮我基于shadcn/ui 和 tailwindcss,实现一个管理后台的UI界面,要求有以下几个页面1. `/` :如果用户已登陆,跳转到/books页面,如果用户没有登陆,跳转到2. `/signup`:系统管理员注册功能,输入姓名、邮箱、密码、确认密码。3. `/signin`:管理员的的登陆页,输入邮箱和密码登陆4. `/books`:单词书管理5. `/admin-users`:管理员管理
单词书管理和管理员管理页面要求登陆后才能查看,并显示对应的侧边栏。侧边栏底部显示用户邮箱 + 退出登陆icon。在Codex CLI中输入上面的提示词,来完成管理后台前端的一个开发工作。
等待 Codex 开发完成之后,查看预览效果。如果有报错或者有其他可以修改的地方,请进行修改。
3.3 登陆注册功能开发
我们这部分来完成后台管理的一个登录注册功能。首先,我们需要去完成表的创建,然后再让 Codex 去实现开发。
3.3.1创建supabase项目
接下来,我们来完成 Supabase 项目的一个初始化。
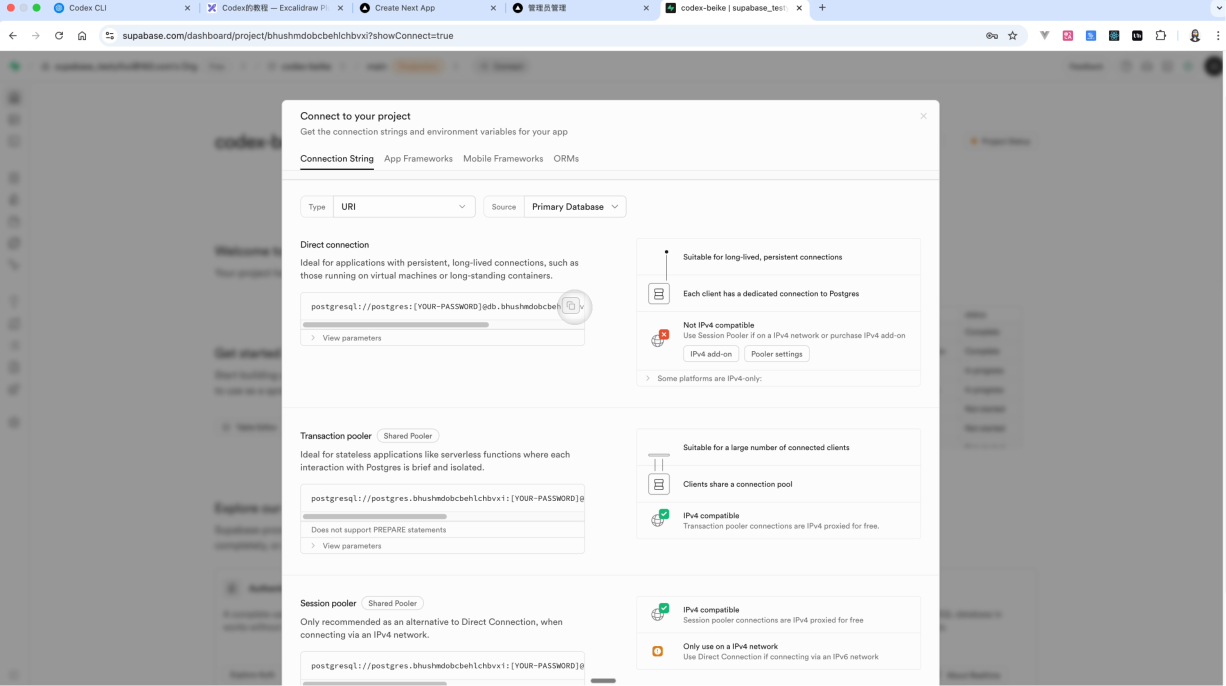
进入到 Superbase 的后台之后,点击 Connect,去复制粘贴数据库的一个连接地址。
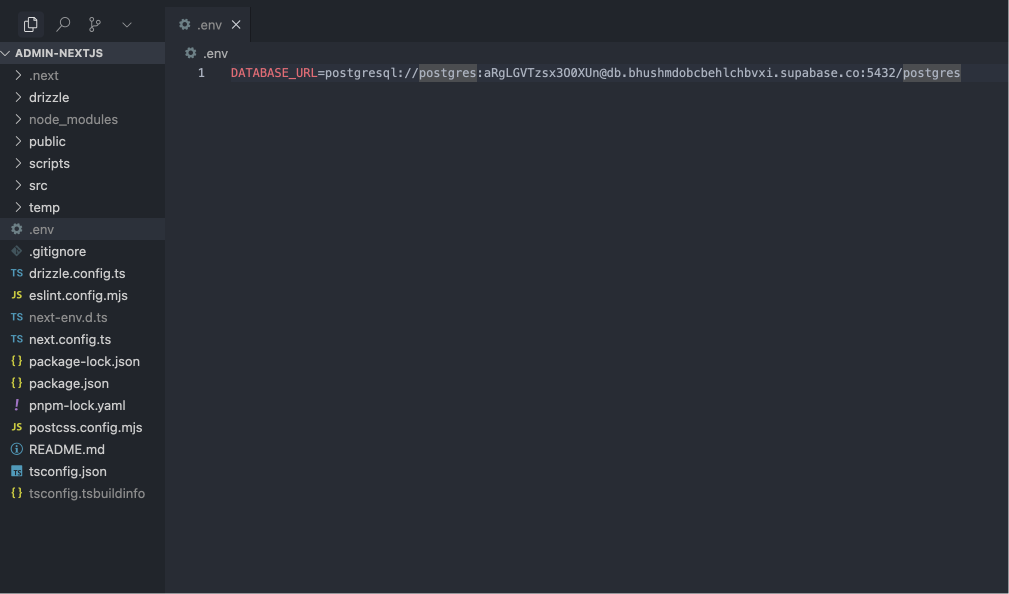
进入到项目当中,创建一个.env 的文件,把刚才的数据库的地址放入到DATABASE_URL当中。
.env:
DATABASE_URL={数据库地址}3.3.2 引入Drizzle ORM
提示词:
给该Next.js项目,安装并引入Drizzle ORM的相关依赖和配置,我需要集成我的supabase的数据库。
我已经在项目中创建了`.env`文件,并且设置了`DATABASE_URL`环境变量。注意,只安装依赖并引入相关配置,不要给我默认创建额外的表。接下来在 Codex CLI 当中输入上述的提示词来完成项目的 Drizzle ORM 的引入。
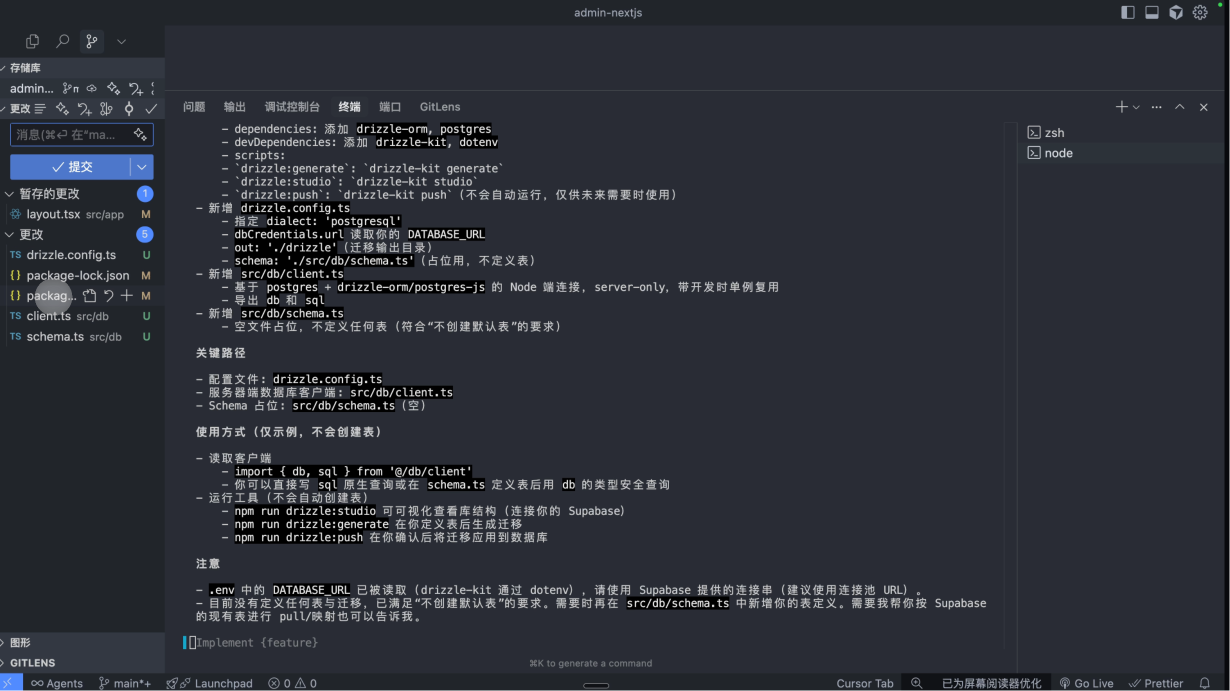
等待 Codex完成开发之后,重启项目,我们来进行一个实际的测试。
3.3.3 实现管理员登陆注册
提示词:
现在请你基于Drizzle ORM,帮我实现管理员注册功能的前后端,要求:
1. 创建对应的管理员数据表 `admin-users`,该表用来保存管理员和系统管理员的的数据, 以及`admin-session`,用来保存用户的session状态,用户登陆态有效期7天。注意:如果数据表中没有任何数据,那么自动跳转到/signup,实现首个系统管理员的注册功能。如果有管理员数据,不允许再二次注册系统管理员,自动跳转到`/signin`。
2. 实现`/signin`页面的登陆逻辑
3. 实现`/admin-users`页面新建管理员 + 管理员列表查看、编辑等逻辑,管理员分为系统管理员和普通管理员。系统管理员可以增加管理员,并且设置管理员为普通管理员或者是系统管理员。如果是普通管理员,无法看到管理员管理这一个侧边栏,同时后端接口也不允许调用。在Codex CLI中输入上面的提示词,完成管理员的登陆注册功能。
开发完成后。记得看一下Codex CLI在后面返回的内容,这很重要。
接下来,如果你去查看一下supabase的数据库里面没有帮你去创建对应的一个数据表的话,你需要去终端执行对应的生成 SQL和创建的一个命令(注意,你这一步可能和我的不太一样,需要根据 Codex 实际给到你的一个语句来输入)
• 生成SQL
终端命令:
npm run drizzle:generate• 应用到数据库:
npm run drizzle:push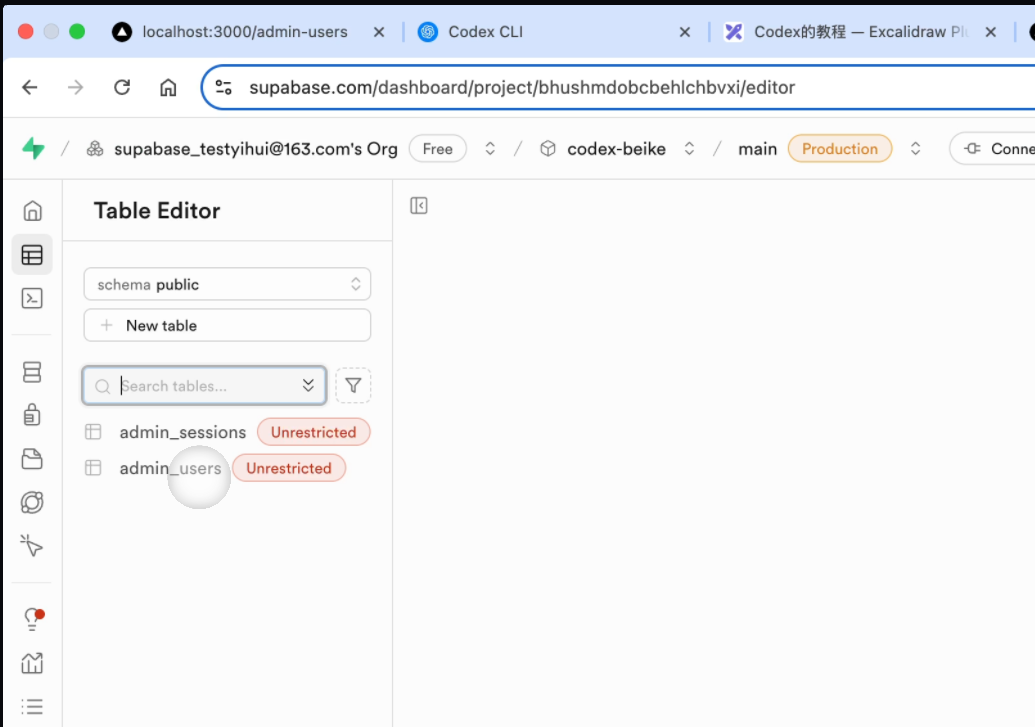
接下来去查看一下supabase的后台。如果你的表创建成功之后,就说明这一步OK了。记得打开RLS策略
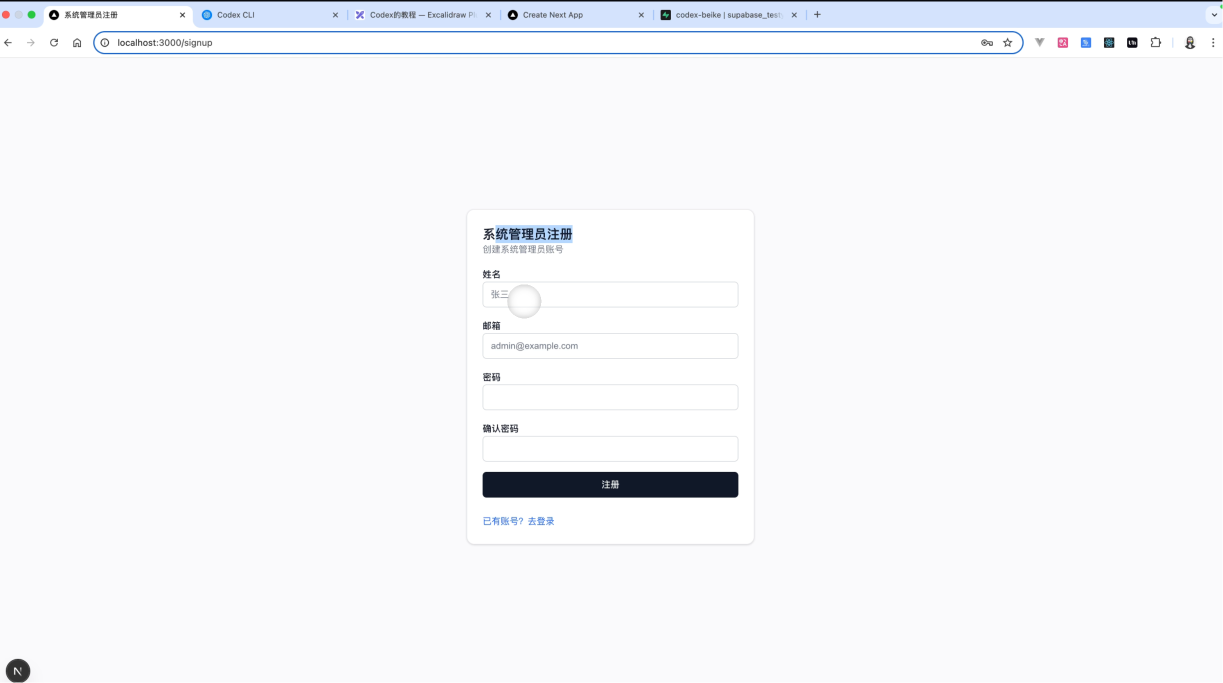
接下来我们进入测试,进入到注册页面,去完成系统管理员的注册工作的测试。
•提示词:
优化一下管理员管理页面1. 系统管理员不能修改自己的状态和修改自己的角色,只能修改它人的状态。2. 优化整体的UI,新建管理员用弹框的方式,同时编辑管理员,也是用弹框,不要在姓名和邮箱后面添加编辑按钮。点击弹框后将数据进行回显后编辑现在的UI有点丑,你可以输入上面的命令,来实现管理员后台的UI优化工作。
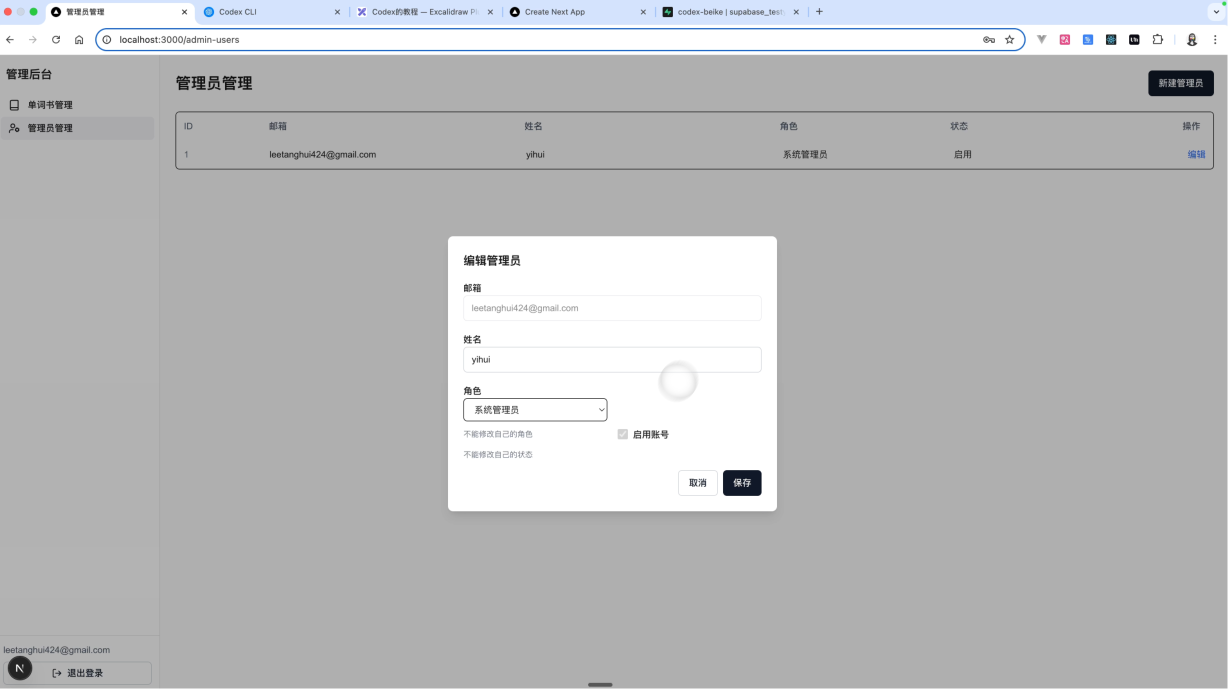
等待AI修改完成之后,我们来进行一个测试。
3.3.4 单词数据清洗+表创建
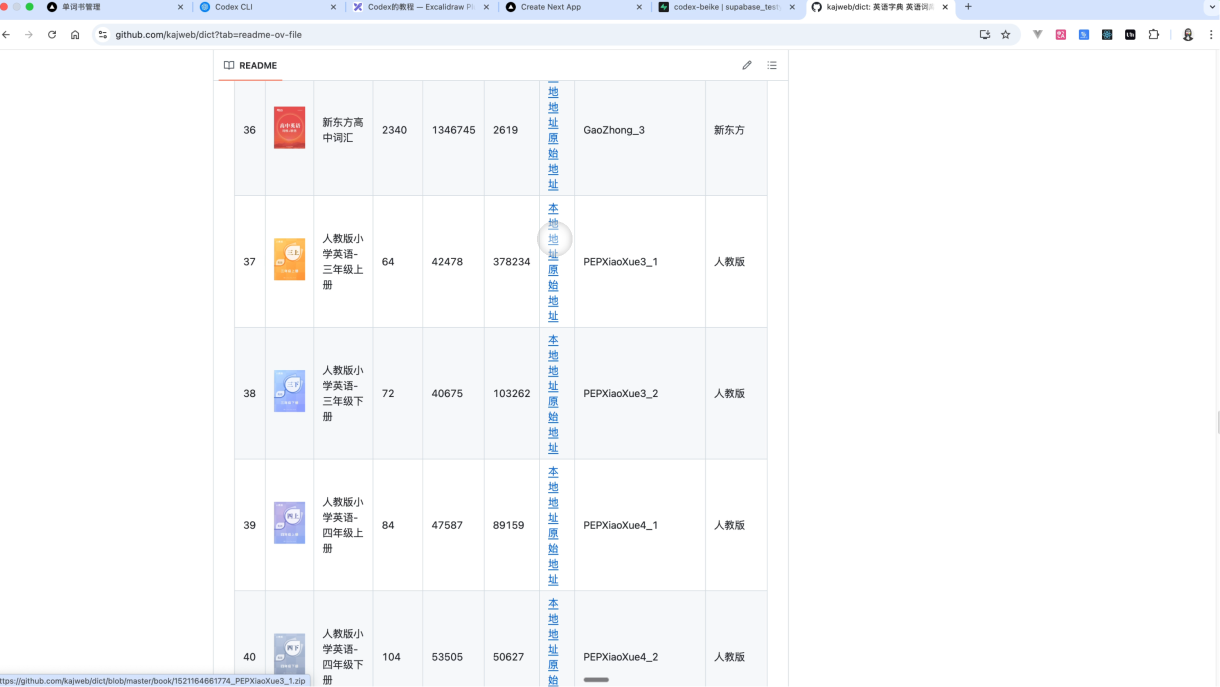
接下来,我们进入到仓库当中,然后去下载对应的一个单词书的数据,进行一个单词书的数据清洗工作。
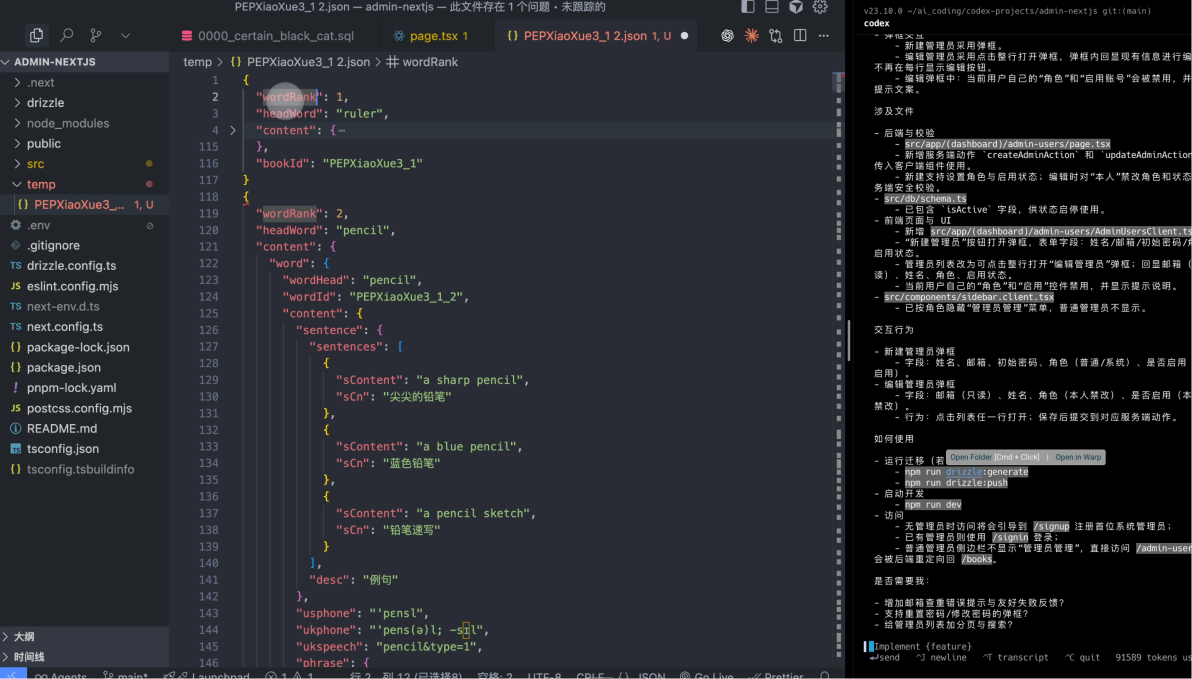
把下载后的一个 JSON 文件拖到你的项目的根目录下的 temp/ 文件夹当中。
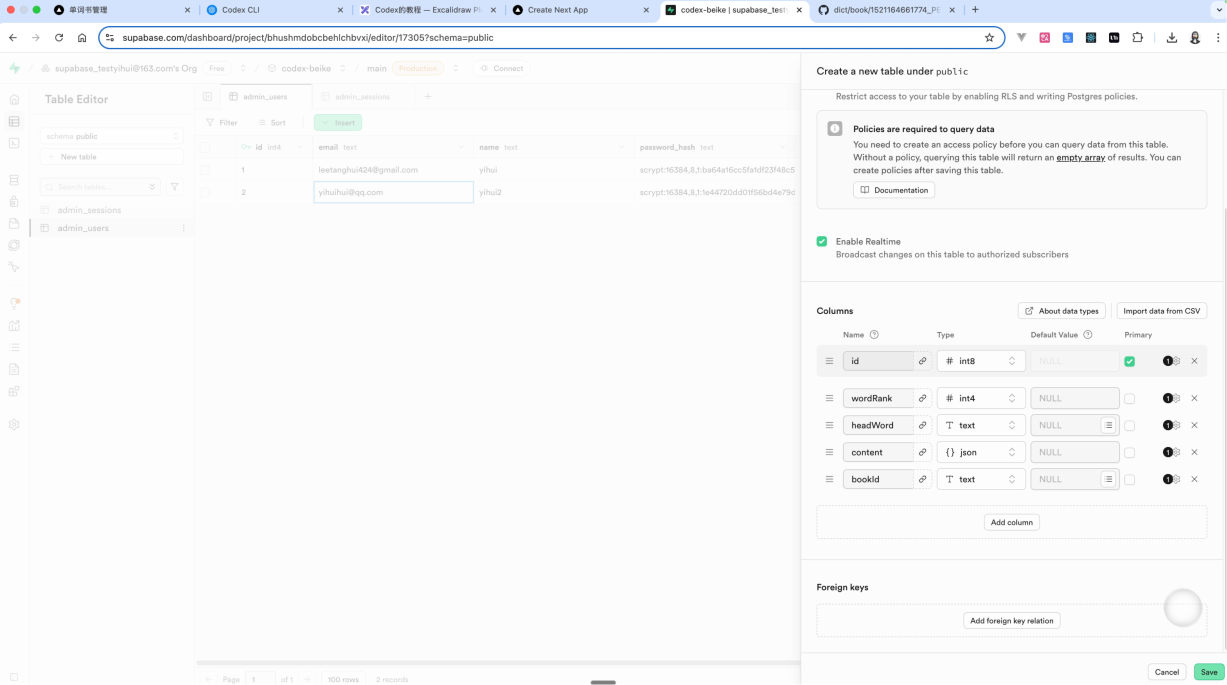
进入到supabase后台—【Table Editor】, 创建对应的数据表 words。输入入上图所示的字段:
wordRank:int4
headword: text
content::json
bookId:text
帮我生成一个node.js脚本,能够把 temp/PEPXiaoXue3_1 2.json 的JSON,处理成为一个csv的格式并保存在同级目下,这是这个json的示例数据:
{复制粘贴两条你的json示例数据}
csv的列包括:wordRank、headWord、content、bookId。将content当做一个json保存在Codex CLI中输入以上的提示词,来让Codex帮我们创建一个数据清洗的脚本的开发。
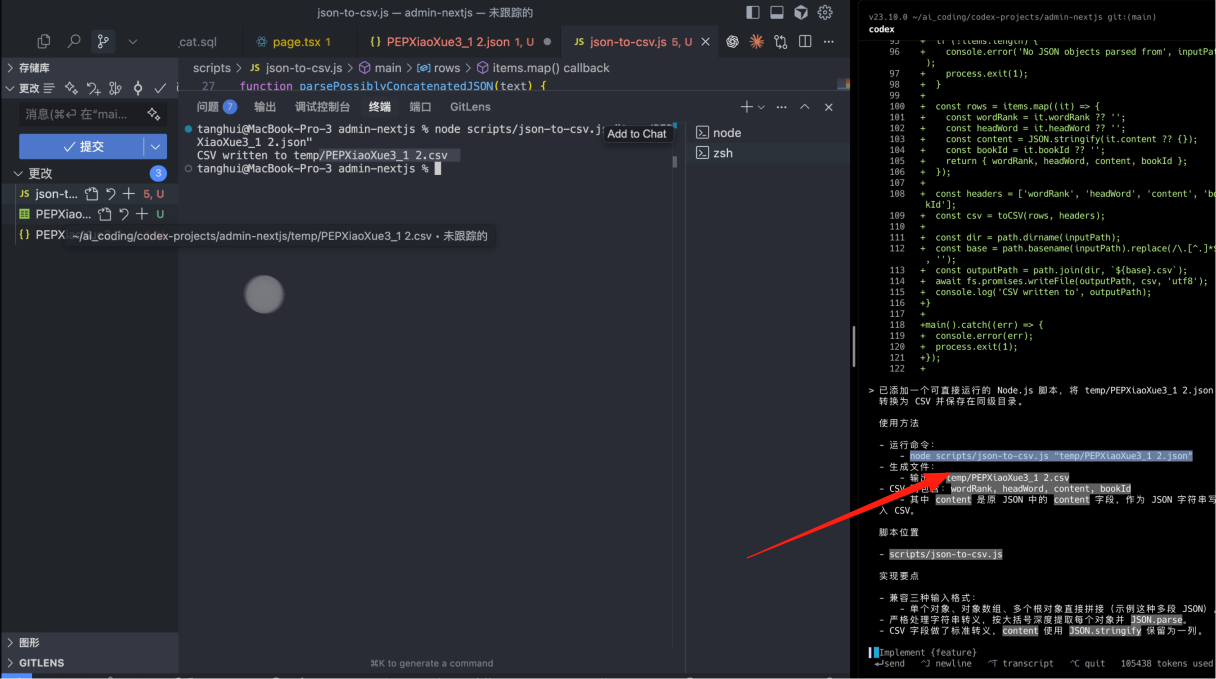
之后去查看 CodeX的一个输出,他会告诉你到底去运行什么命令来生成 csv 的一个数据。然后去到我们的终端里面执行这一条命令。
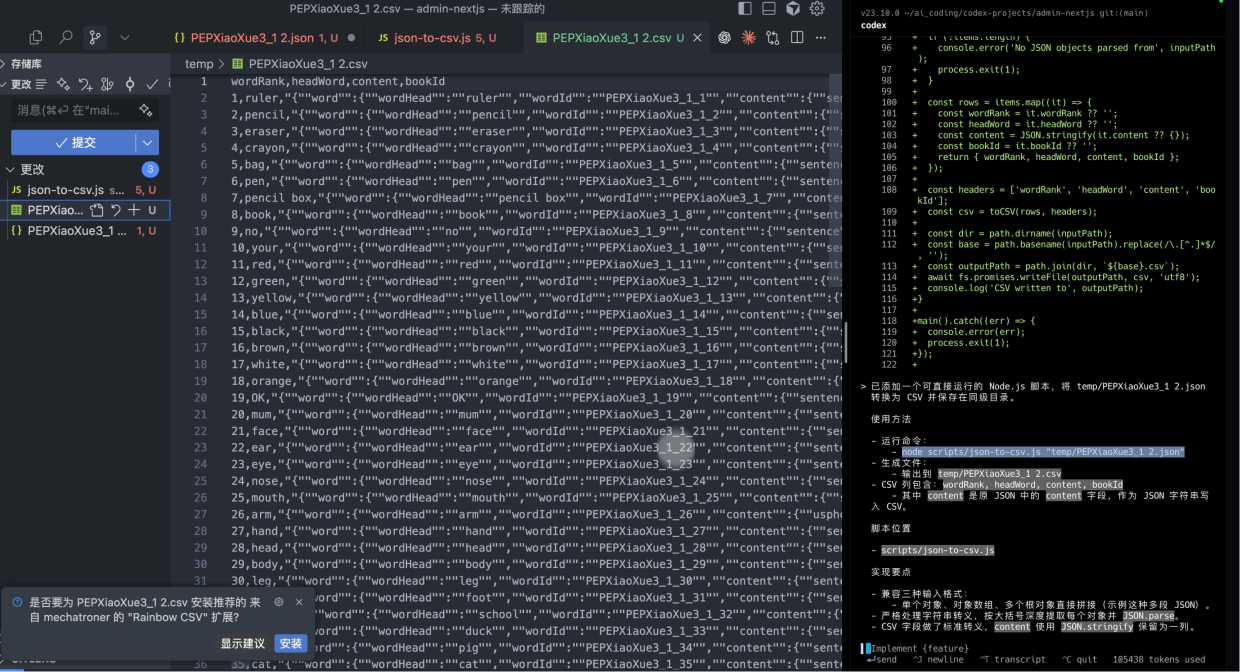
如果顺利的话,你就会发现增加了一个.csv的数据。
3.3.5 上传数据
• 点击 improt data from csv
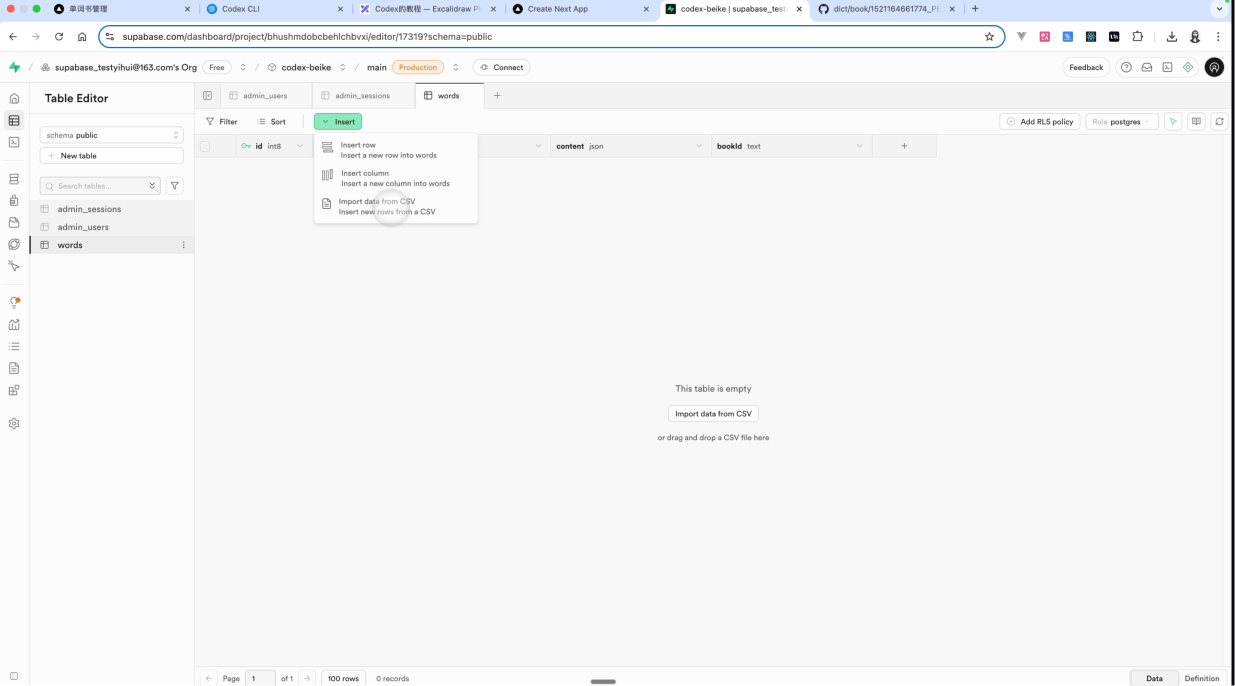
• 上传你的csv
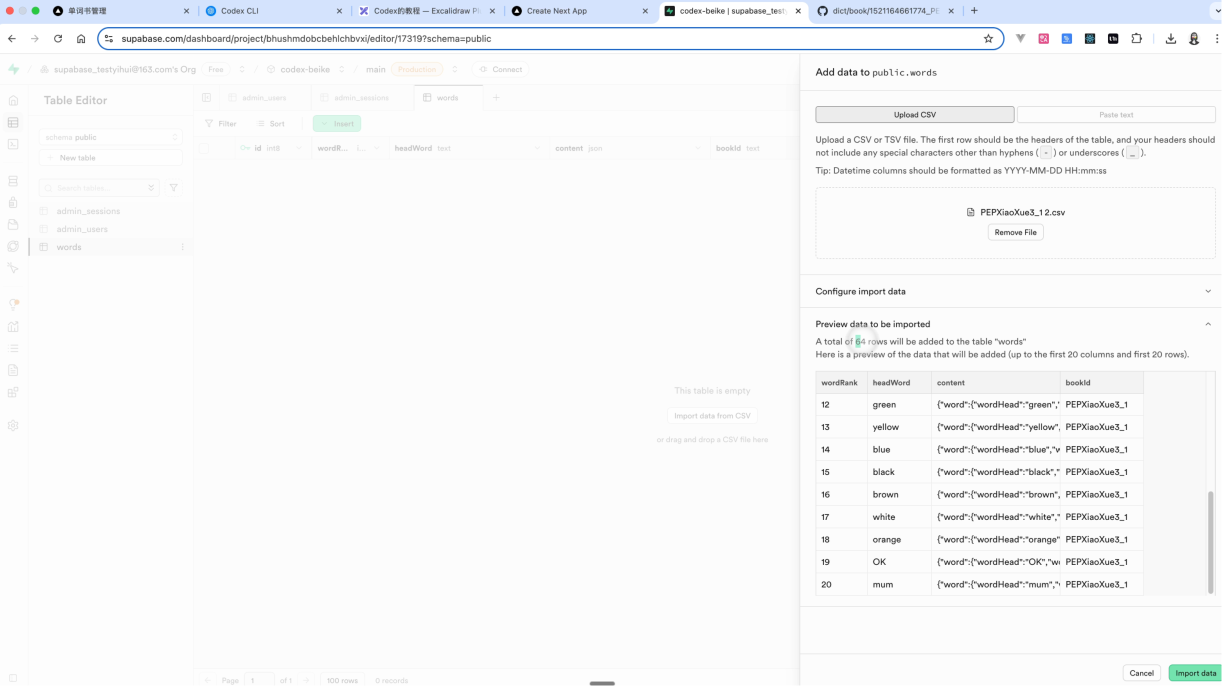
• 验证是否导入成功
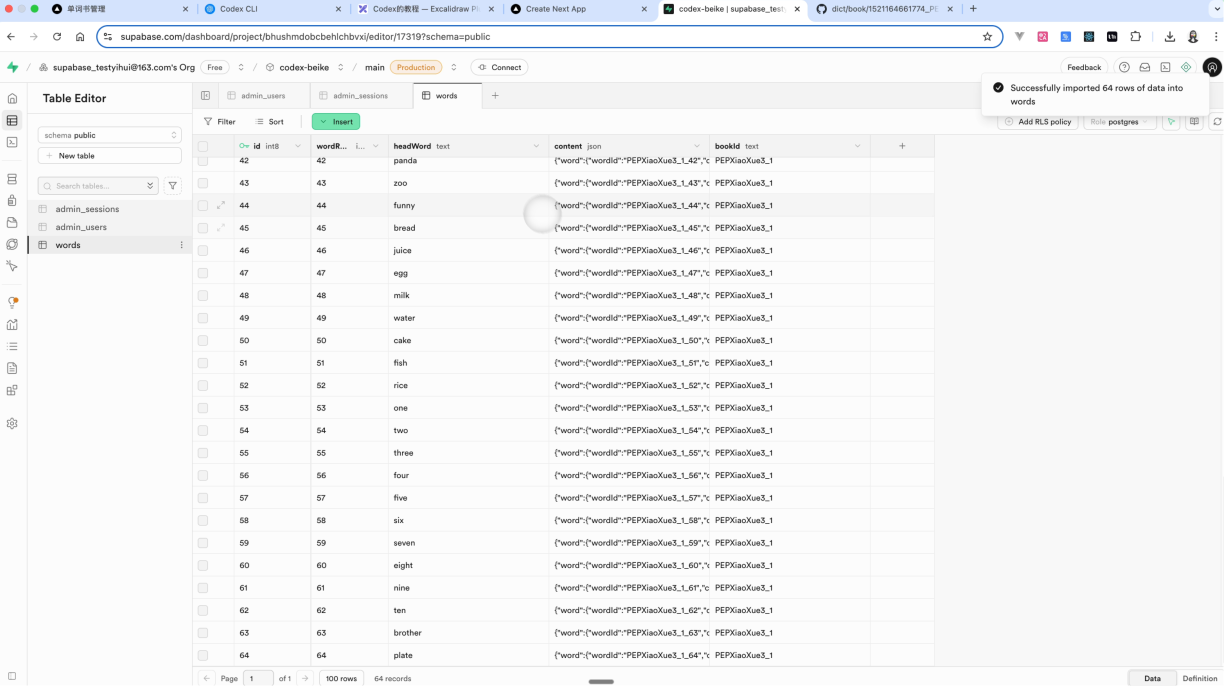
按照上面的步骤去导入这样的一份CSV数据,你就会发现数据库里面成功导入成功了。
3.3.6 创建单词schema
•提示词:
我在 supabase 后台创建了一个 words 的表。请你帮我在项目中定义该表的一个 schema。这是表的定义:
```sql{输入你的sql语句}```3.3.7 单词书管理功能
• 提示词:
请你帮我创建单词书的录入功能和单词书管理功能,要求:1. 用户点击新建单词书后,出现弹框,要求用户输入标题、单词数量、封面url、bookId、标签(逗号分割)。2. 单词书用个表渲染封面、标题、单词数量、bookId信息。用户点击编辑可以弹出编辑弹框。3. 帮我完成单词书的`books`的表创建工作,并实现表的迁移操作4. 通过bookId实现和words这个表的关联关系在CodeX CLI中输入上面的提示词来完成单词书的开发。
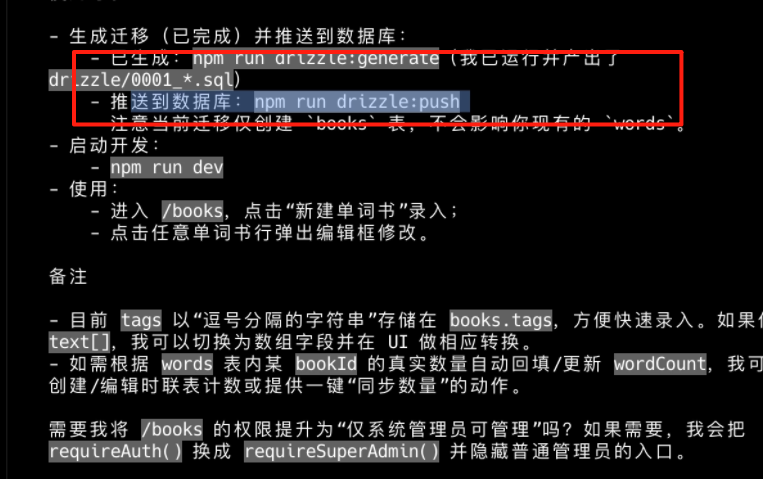
等待开发完成之后,如果你的数据库里面没有创建新的表,你需要去查看 Codex 给你的一个命令,以实现表的语句的创建和推送到数据库的一个操作。
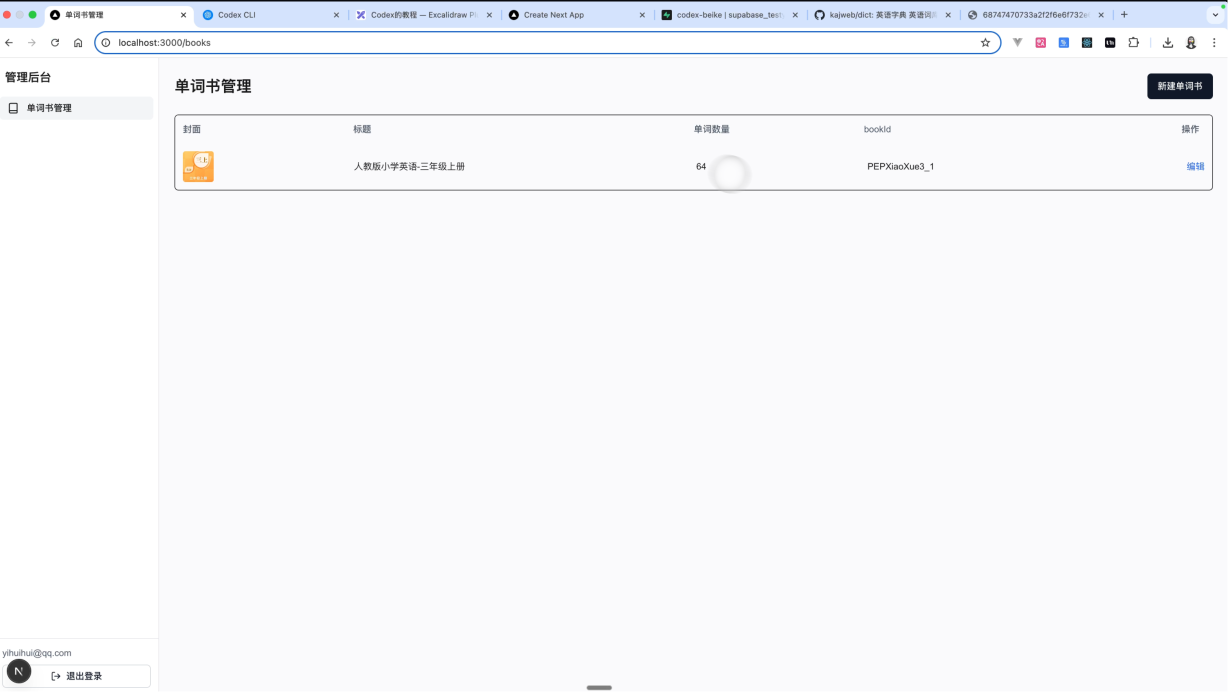
之后对单词书管理这个页面进行一个测试工作。
3.3.8 删除单词书功能
•提示词:
完成删除单词书的功能,同时删除books这张表中对应的单词书,以及words这张表中相同booksId的所有数据最后,我们来输入上面的提示词,完成单词书的一个删除功能。
4. Codex实战:单词书H5
4.1 初始化项目
为了简化Drizzle的安装和登录注册功能,我们这一次使用这个官方的模板来实现初始化。
在命令行中输入
•提示词:
npx create-next-app nextjs-typescript-starter --example "https://github.com/vercel/nextjs-postgres-auth-starter"
项目安装成功之后,复制.env.example这个文件为.env,然后输入上面的一个环境变量。
第一个环境变量是数据库的连接地址,第二个环境变量是点击上方的链接生成即可。
运行一下命令跑起来整个项目:
pnpm run dev
然后进行登录注册的一个测试。
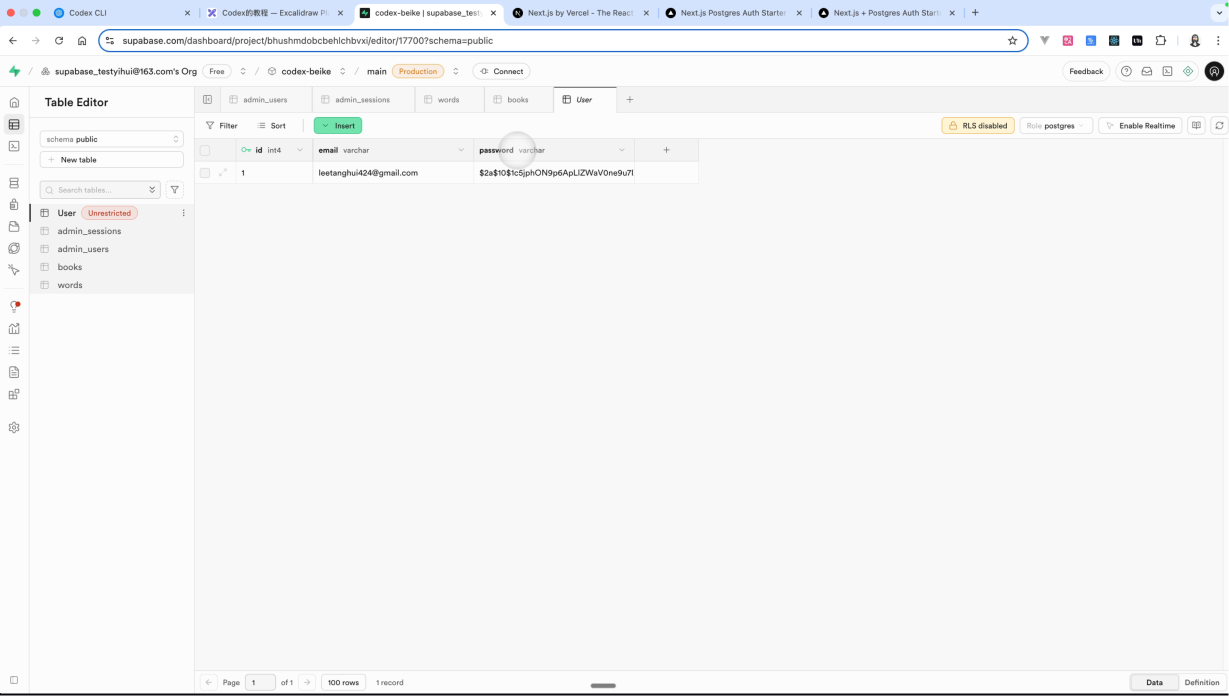
注册成功之后,可以看一下你的 Supabase 的后台。
如果你的表当中有了新注册的一个用户,那说明你的这个项目确实已经完成了。
4.2 规划文档
提示词:
帮我编写一个需求文档,放到 @docs/prd.md中。我希望做一个h5的学英语单词的项目,要求:1.底部有2个tab栏,分别是首页、我的。
2.【首页】如果用户已经登陆,展示「最近学习」,也就是最近学习单词书(如果没有数据不展示该模块),点击后用户可以继续学习,「最近学习」下方,是所有单词书,展示所有单词。
3.【首页】如果用户没有登陆,只展示单词书,用户点击后跳转到【我的】页面,弹出登陆的popup,输入邮箱和密码实现登陆和注册。登陆注册的代码参考已有逻辑 @app/login/page.tsx 和 @app/register/page.tsx
4.【我的】页面显示用户邮箱、退出登陆,包括学习进度
5. 用户点击进入单词学习后,从最近学习的单词的下一个开始进入学习,以单词卡片的方式,用户可以点击下一个按钮实现切换。单词的json的完整数据如下,请你选择合适的字段实现渲染。单词卡片要尽可能的简单,只展示一个示例,详细学习可以点击单词,进入到单词详情页渲染。
```json复制一个单词的json数据```
请你帮我写一个详细的需求文档,并对各个页面画线框图展示UI布局输入上面的提示词,实现需求文档的开发。这是对应的需求文档 prd.md。你可以根据自己的需要,然后去进行一个修改。
接下来请你帮我编写 docs/tech.md,,这是个技术文档,要求:1.目前数据库中已有两个数据表,分别是`words`单词数据,和`books`单词书数据。
表定义分别是:```sqlwords表的SQL语句```
```sqlbooks表的SQL语句```
2.根据 @docs/prd.md,完成用户背单词的其他表的设计工作
3.认真完成一份涉及前后端的技术文档输入上面的提示词来完成技术文档的一个开发工作。下方是对应的技术文档。
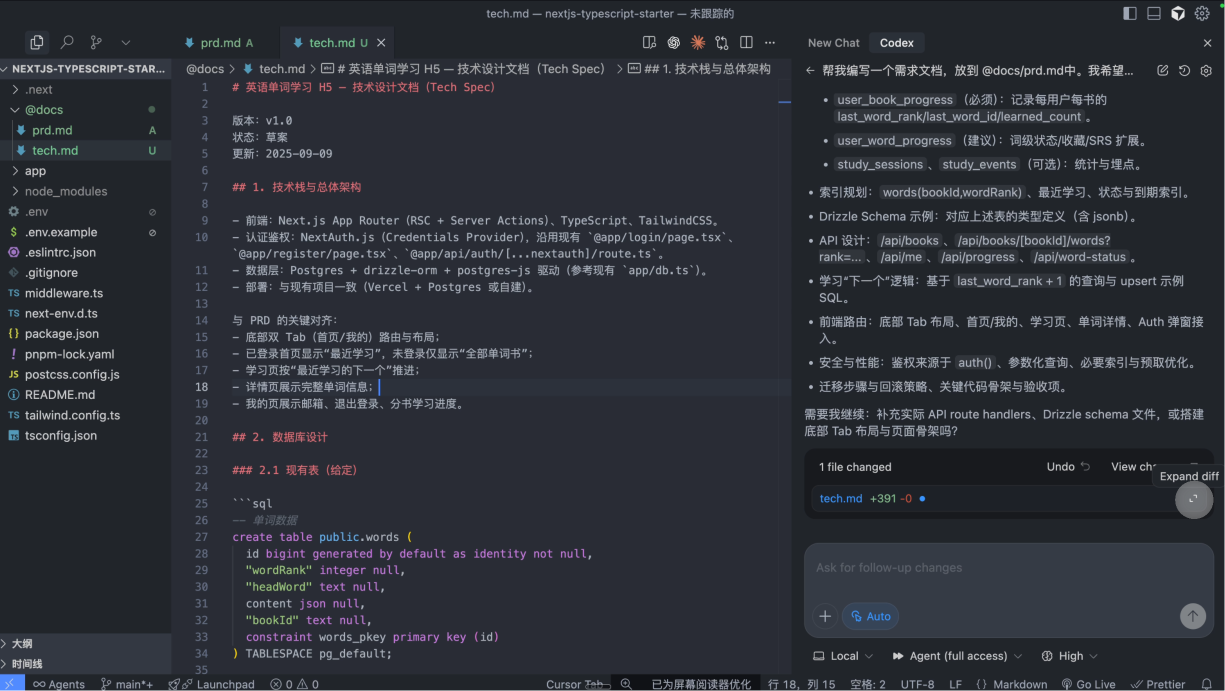
4.3 完成数据表创建
• 提示词:
开始编写数据库迁移脚本,实现表的schema设计和迁移在上方完成了对应的一个数据的技术文档创建之后,我们来让他去编写数据库迁移的脚本,实现 schema 的设计和迁移。
提示词:
请你根据 migrations/ 文件夹下创建的SQL语句,去创建对应的Drizzle的Schame文件,并且完成迁移操作,实现数据库的远程创建。如果数据库中没有新增的表,可以再输入上方提示词。
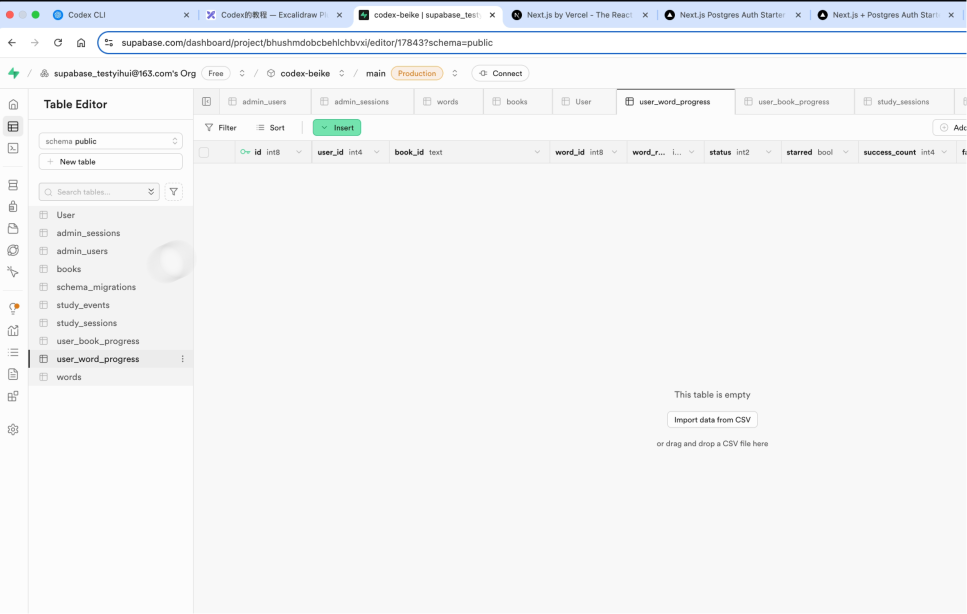
4.4 实现UI开发
• 提示词:
现在请你根据 @docs/prd.md 实现前端的UI页面开发,完成现在需求文档中的所有页面。数据先使用mock数据代替,数据结构可以参考 @docs/tech.md 的数据库中的表结构代替。UI组件使用shadcn/ui这一步UI开发阶段,我们使用的是Claude Code去实现,因为Claude Code开发出来的UI效果要比CodeX强很多。开发完成之后,就进入到实际的测试阶段,进行一个优化。
注意下方提示词只是针对我的AI开发出来的效果进行的一个优化。你自己开发出来的需要根据自己的效果进行调整。
• 优化提示词1:
移除掉用户登陆后进入到 /protected 页面的重定向,不需要• 优化提示词2:
目前word单词中的content字段不对,单词的字段的json请你参考这个真实的数据
```复制content字段的真实json数据```
请你根据数据结构,修改对应的UI展示。同时单词卡片的宽度调整为屏幕宽度。• 优化提示词3:
单词书是有封面的,包括最近学习也是有显示封面的。请您根据真实的数据以示例替换。
```复制books的1-2条json数据```
请使用上面我给你的数据去渲染首页单词书。封面使用 `cover_url` 实现渲染。4.5 接入书籍后端数据
•提示词:
现在让我们获取单次数的数据,从 `books` 表中获取全部书籍的数据,并渲染在首页。
这是 `books` 的定义,请你定义 schema 并且完成。
```sql复制你的books数据表的SQL定义```输入上面的提示词去接入真实的一个数据库的数据。
4.6 接入单词书学习进度
•提示词:
现在让我们开始实现单词书的学习逻辑。点击单词书后,通过 `bookId` 获取 `words` 表的数据,并开始进入学习模式。这是 `words` 表的一个 SQL 定义。
```sql复制words表的SQL定义```
同时,请你创建对应的表的 schema。开发完成后,进行测试并对bug进行修复
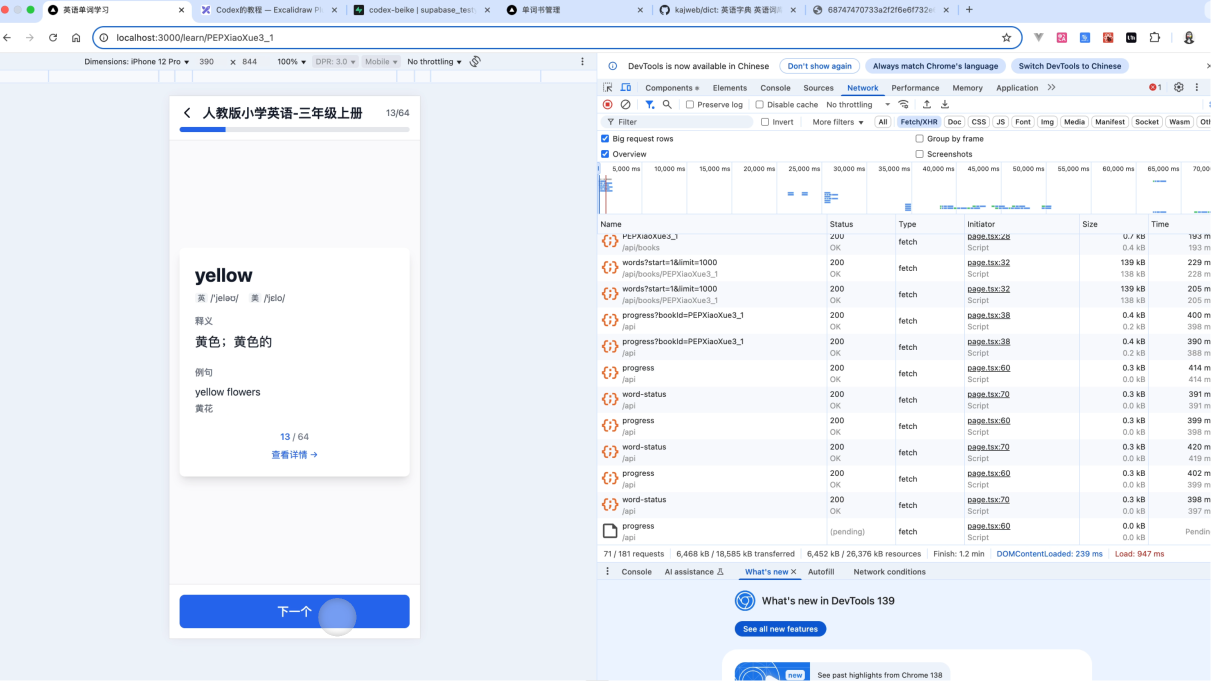
4.7 接入发音
提示词:
请你帮我实现单词的发音功能,支持英式发音和美式发音。点击小喇叭的图标进行发音请求的接口如下:
有道英语发音接口https://dict.youdao.com/dictvoice?audio={word}&type={1|2}type 1 为英音 2 为美音
请你替换 audio 参数和 type 参数。输入上面的提示词,来完成单词的发音功能的开发。如果说开发完成之后,进行一个实际的测试。
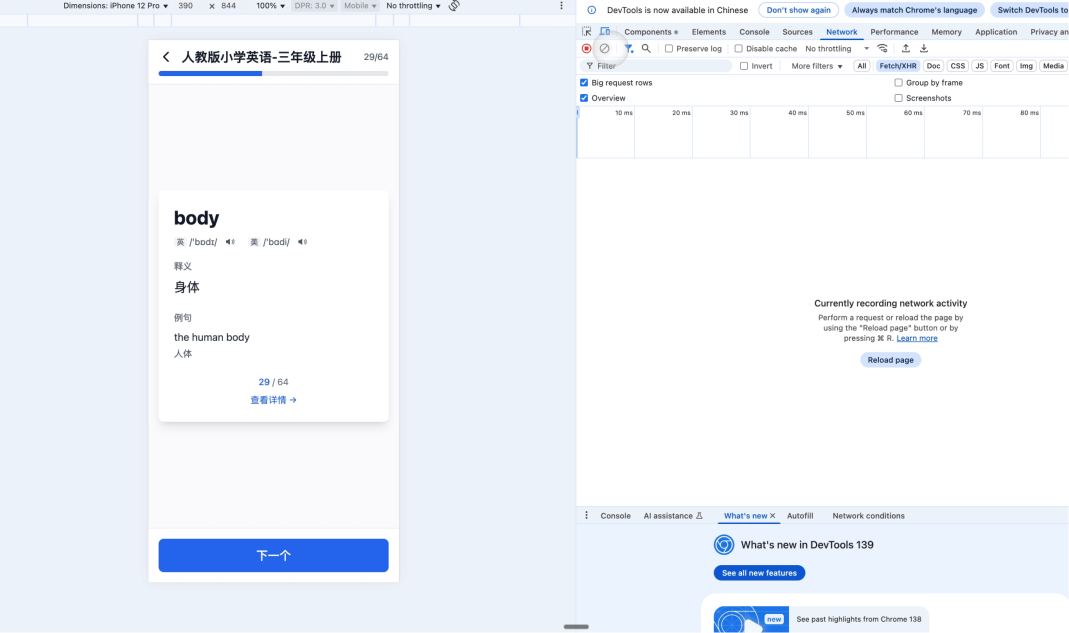
目前这个产品还是有很多可以优化的点。比如说,加入骨架图、加入单词的复习流程的算法,包括类似艾宾浩斯记忆一个记忆算法等。你可以自己去扩展这个产品,或者把它修改成小程序或iOS 应用,都是可以的。加入一些有趣的玩法。
项目源码
1. 管理后台:下载链接
2. 前端H5:下载链接