用DeepSeek + Qwen-VL:做个AI待办事项应用
/ 11 min read
一.作品展示
在本期的教程当中呢,我们将会学会如何去制作一个AI版本的待办事项应用,传统的待办事项应用都是像下面这样:每添加一个新的任务,然后增加一条。
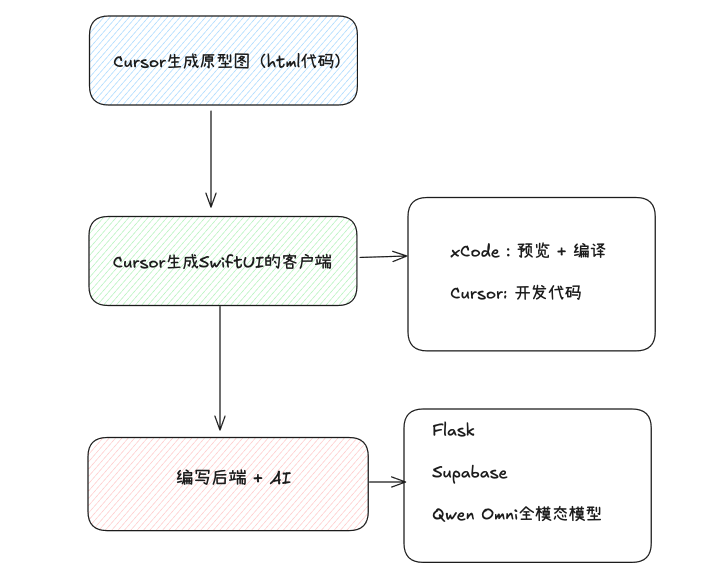
下面我们将这个应用改为Al版本的待办事项应用,能够一次性说完所有今天要做的事情, 然后ai会自动的帮你拆解今天的待办内容,并且你能够支持上传手写图片进行解析。
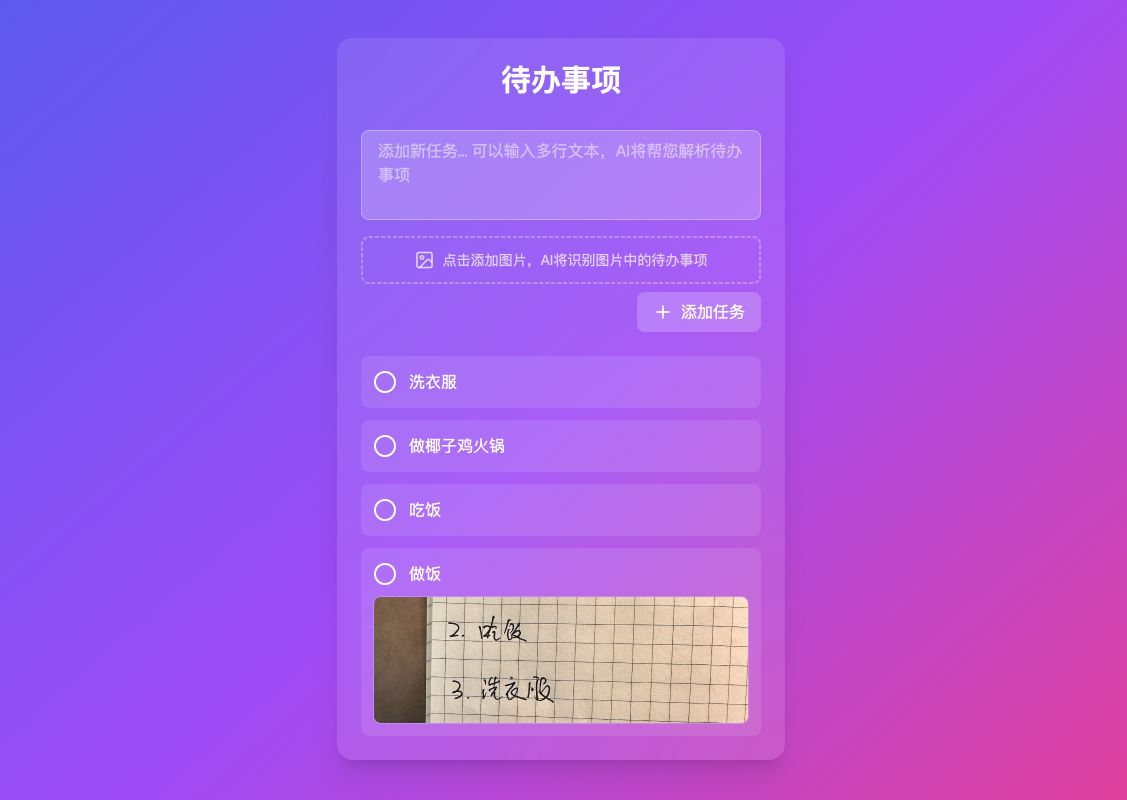
二.流程
我们将分别使用DeepSeek-v3和Qwen-VL模型去实现这个应用:
1. 先使用DeepSeek-v3支持长文本输入
2. 替换DeepSeek-v3为Qwen-VL模型,让其支持图像理解能力
三.项目实战
1.1 下载项目(用vscode/cursor打开)
我们直接使用TODO应用的源代码和 supabase的后端服务,请你确保:
1. 下载源代码
2. 在.env.Local 中填入supabase环境变量
3. 数据库中有创建 todos这张表
4. 有创建 my-todo这个Bucket用于保存图片
5. 有打开 todos 这张表的RealTime实时功能
1.2 运行项目
• 安装依赖(vscode/cursor的终端(terminal)):
pnpm install• 运行项目:
pnpm dev如果运行成功,在浏览器访问 localhost:3000,你应该就可以看到这个应用成功的运行起来了。完成登陆注册后,我们来完成这个应用的改造吧!
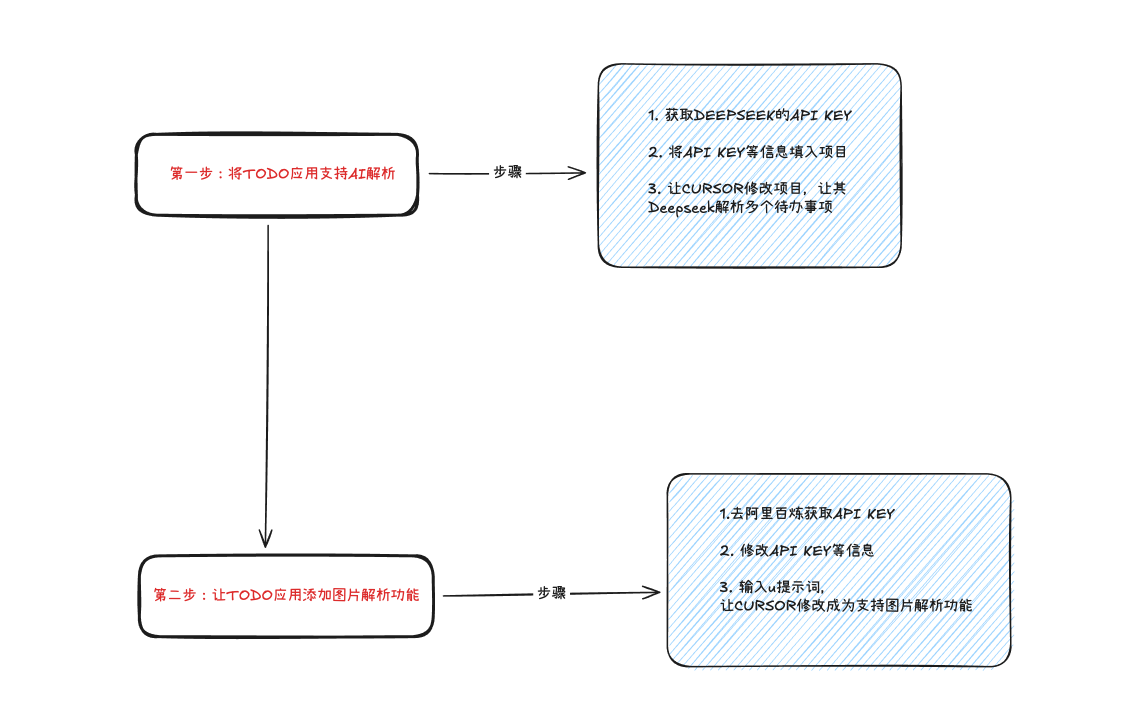
2.1 获取API KEY
• 访问DeepSeek官网,点击API开放平台
• 如果你没有用量,那可能需要充值一下(反正之后你肯定也会用到DeepSeek)
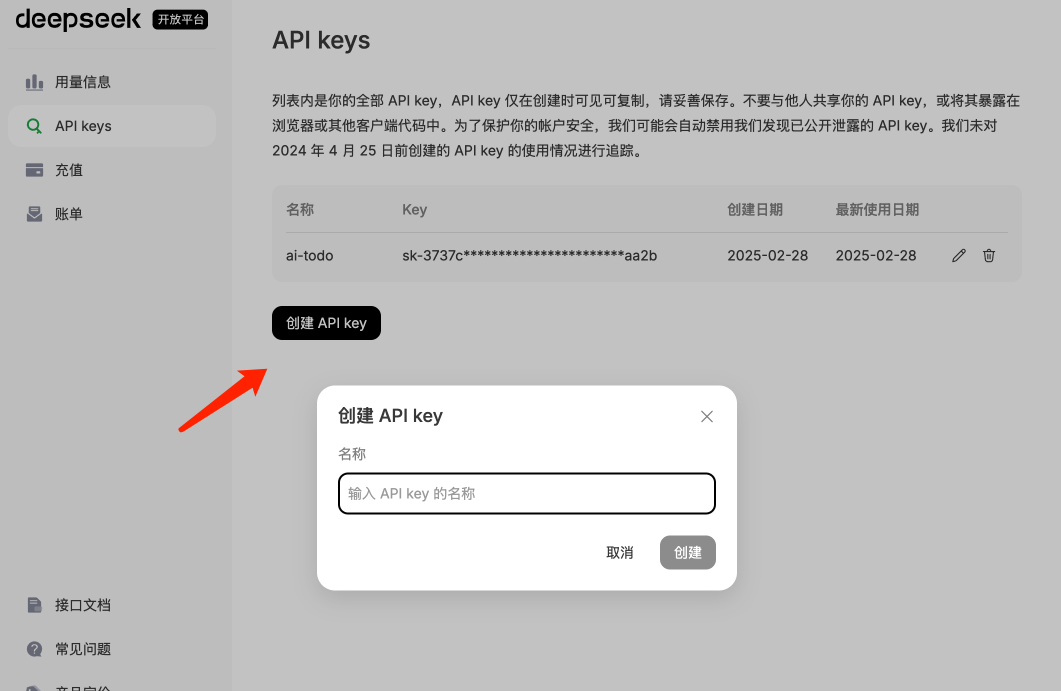
然后在API Keys这里点击「创建APIKey」,并记得保存好这个API Key!
2.2 在项目中增加环境变量
- 打开**.env. local** 文件,在项目中新增deepseek相关的环境变量
# supabaseNEXT_PUBLIC_SUPABASE_URL=your_supabase_urlNEXT_PUBLIC_SUPABASE_ANON_KEY=your_supabase_anon_key
# deepseekOPENAI_API_KEY=your_deep_api_keyOPENAI_BASE_URL=https://api.deepseek.com注意:以上代码中supabase和deepseek的API key和URL需要自己去对应网站的后台设置查找并复制替换以上代码中默认的变量值!
- 在supabase中获取 service_role,并新增到环境变量中
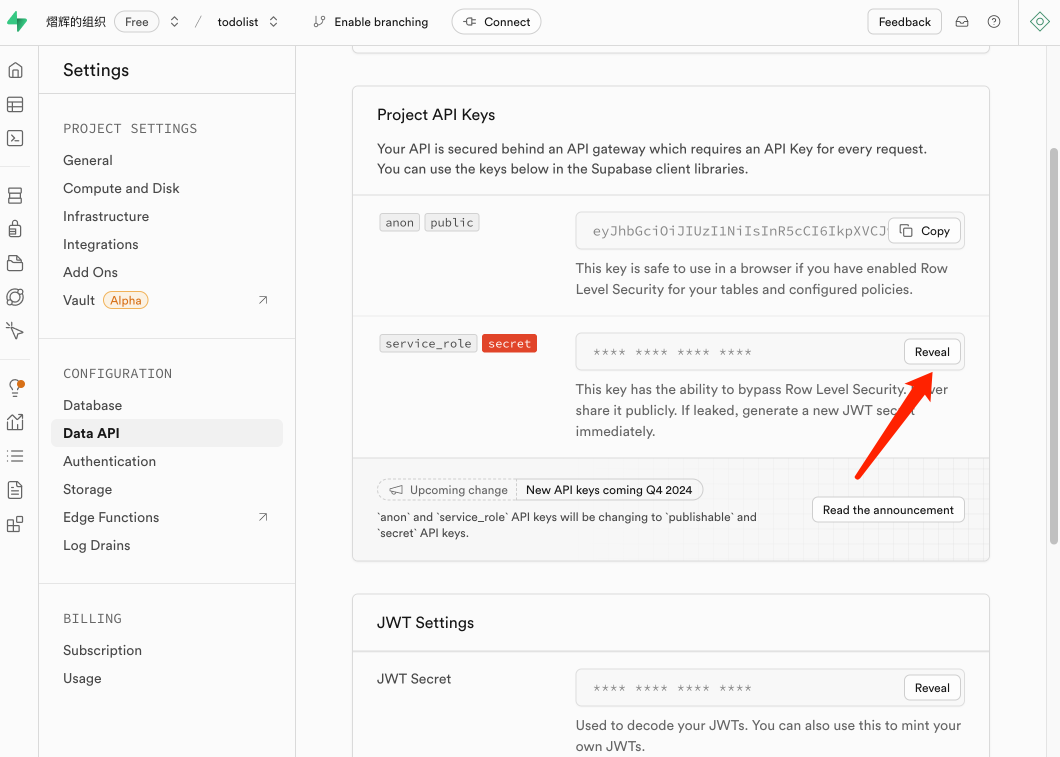
现在你的 .env.local 环境变量文件应该长这样:
# supabaseNEXT_PUBLIC_SUPABASE_URL=your_supabase_urlNEXT_PUBLIC_SUPABASE_ANON_KEY=your_supabase_anon_keySUPABASE_SERVICE_ROLE_KEY=your_supabase_service_key
# deepseekOPENAI_API_KEY=your_deep_api_keyOPENAI_BASE_URL=https://api.deepseek.com2.3 让Cursor修改
在Cursor中输入下面的提示词,让Cursor Agent修改
提示词:
@page.tsx 我现在想给页面添加以下几个功能:1. 我想把输入框变成文本输入,能够支持更多文本输入,默认3行2. 移除掉前端直接通过增加任务的方式,而是请求后端3. 我希望输入文本之后能够将文本和uid发送到后端,然后后端调用环境变量中的openai的接口,OPENAI_API_KEY和OPENAI_BASE_URL已经在环境变量中了,根据文本调用ai解析我的所有待办事项,使用supabase的服务端API_KEY插入数据(环境变量:SUPABASE_SERVICE_ROLE_KEY),如果有多条插入多条,如果只有单条插入单条4. 模型采用deepseek-chat的模型5. 调用ai服务请采用openai的node.js sdk2.4 测试效果
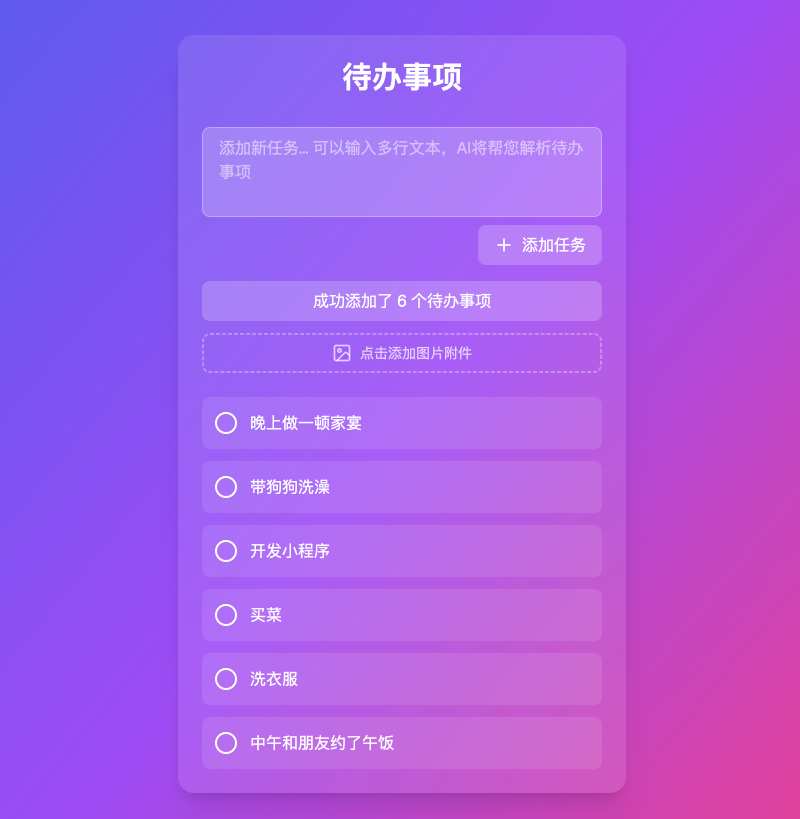
我们可以输入一整段待办事项,来测试一下Al是否能解析清楚我要做的事情:

这个效果非常完美!DeepSeek YYDS
3. 替换Qwen的视觉模型
接下来我希望我的待办事项能够支持图片解析能力,也就是我上传一个我手写的图片者截图。它能够自动的解析成为多个待办事项。这个时候我们就需要替换DeepSeekB 型成为一个支持视觉的模型,这边我选用Qwen的视觉模型。
为什么要使用视觉模式?
-DeepSeek默认的V3或者R1模型是不支持视觉能力,它是语言模型。
3.1 获取API KEY
首先我们需要去到阿里百炼获取到APIKEY,首先进入到阿里云百炼平台。点击API-KEY
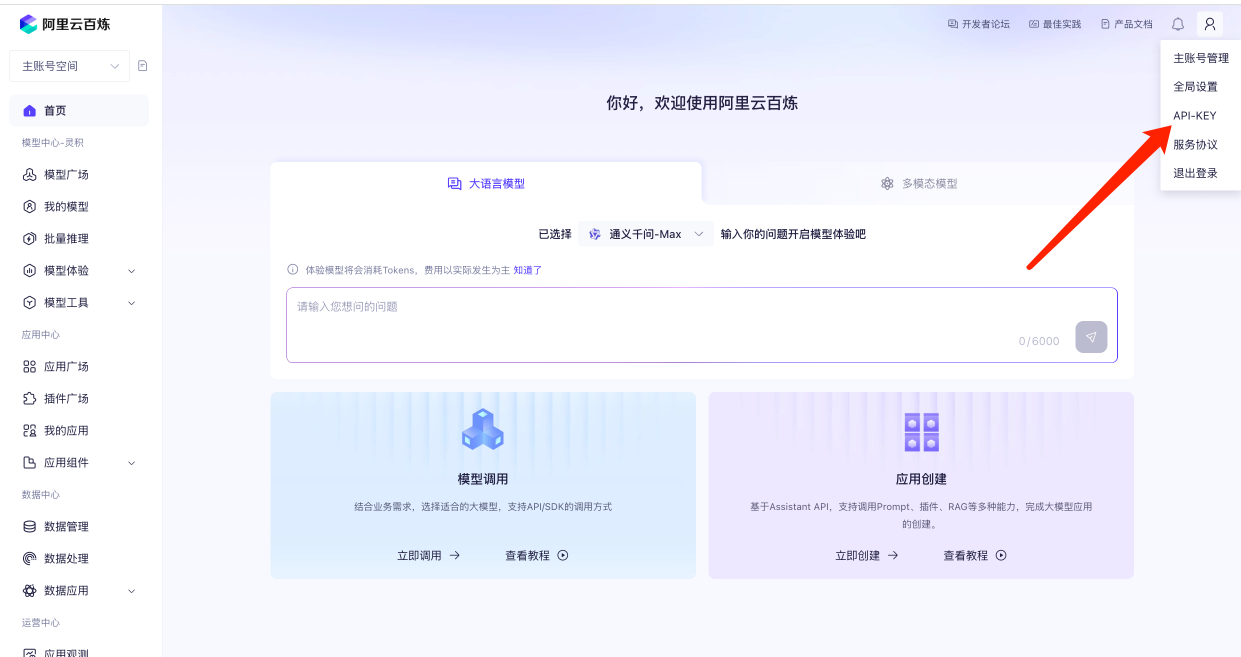
点击创建获取到你的API KEY,记得保存好这个API KEY哦。当你创建了这个API KEY
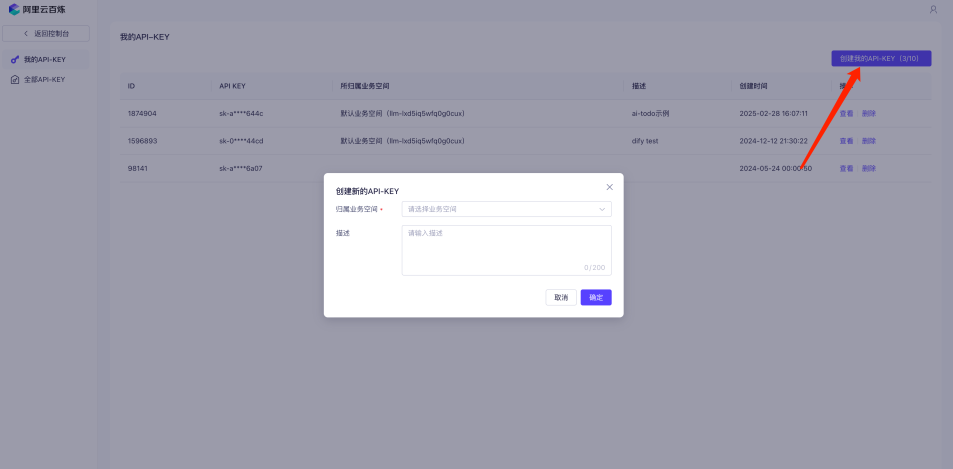
3.2 选择模型
接下来,我们可以进入到首页的模型广场,选择一个有【图片理解】能力的模型
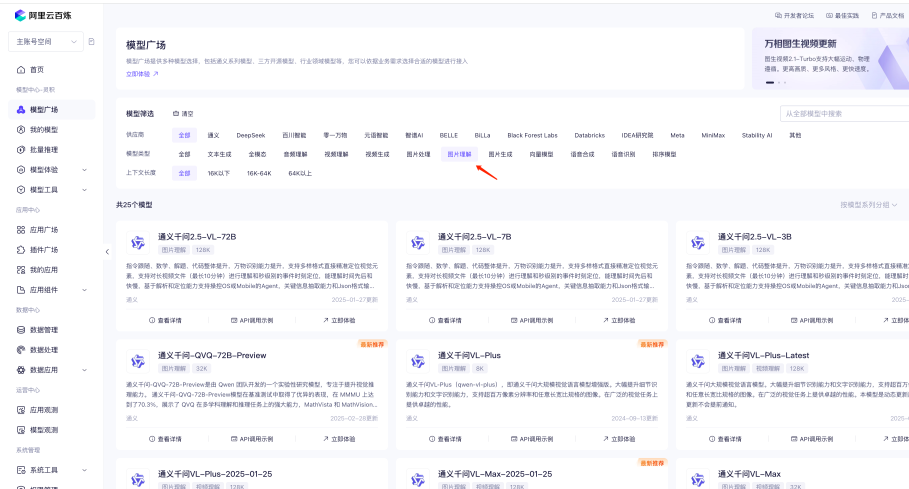
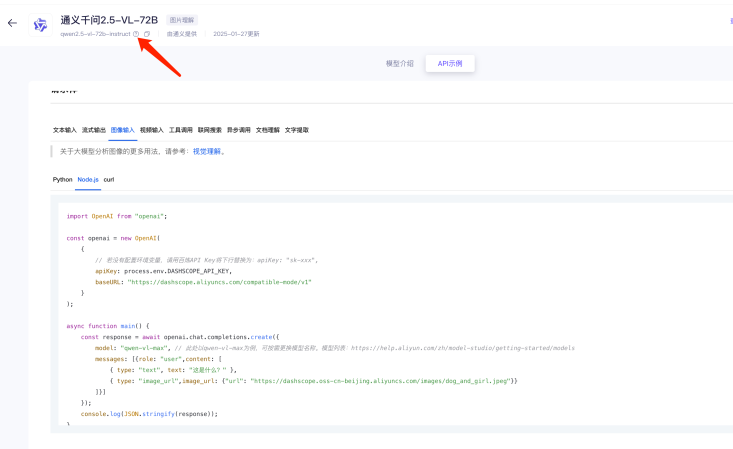
这边我们来使用通义干问2.5-VL-72B模型,点击进入「API调用示例」,有2个内容是你需要记住的:
1. 模型名称: qwen2.5-vl.72b-instruct (需要在提示词中告诉Cursor)
2. 模型调用地址: https://dashscope.aliyuncs.com/compatible-mode/v1 (在环境变量有使用到)
3.3 在项目中修改环境变量
到 .env.Local 中,修改对应的环境变量:
-
修改OPENAI_API_KEY 为你在阿里云百炼平台中获取到的API KEY
-
修改 OPENAI_BASE_URL 为: https://dashscope.aliyuncs.com/compatible-mode/v1
现在你的 .env.Local 应该长这样:
# supabaseNEXT_PUBLIC_SUPABASE_URL=your_supabase_urlNEXT_PUBLIC_SUPABASE_ANON_KEY=your_supabase_anon_keySUPABASE_SERVICE_ROLE_KEY=your_supabase_service_key
# deepseekOPENAI_API_KEY=your_aliyun_apikeyOPENAI_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v13.4 让Cursor修改
在Cursor中输入下面的提示词,让Cursor Agent修改
现在我希望支持图片理解能力,要求如下:1. 用户能够直接上传图片到supabase的bucket中,然后大模型需要能够解析图片中写的待办事项,将待办事项插入数据库。2. 用户可以直接上传图片,不用写任何文字;也可以同时上传图片和文字3. 不再使用deepseek的模型,而是全部替换为qwen2.5-vl-72b-instruct,apiKey和baseURL依然使用环境变量中的OPENAI_API_KEY和OPENAI_BASE_URL。我已经将其替换成为了qwen2.5-vl-72b-instruct对应的apiKey和baseURL4. 只抽取用户图片 + 文字中的待办事项,并且以原文和源语言显示,不要添加额外的内容。5. 提示词请使用中文3.5 测试效果
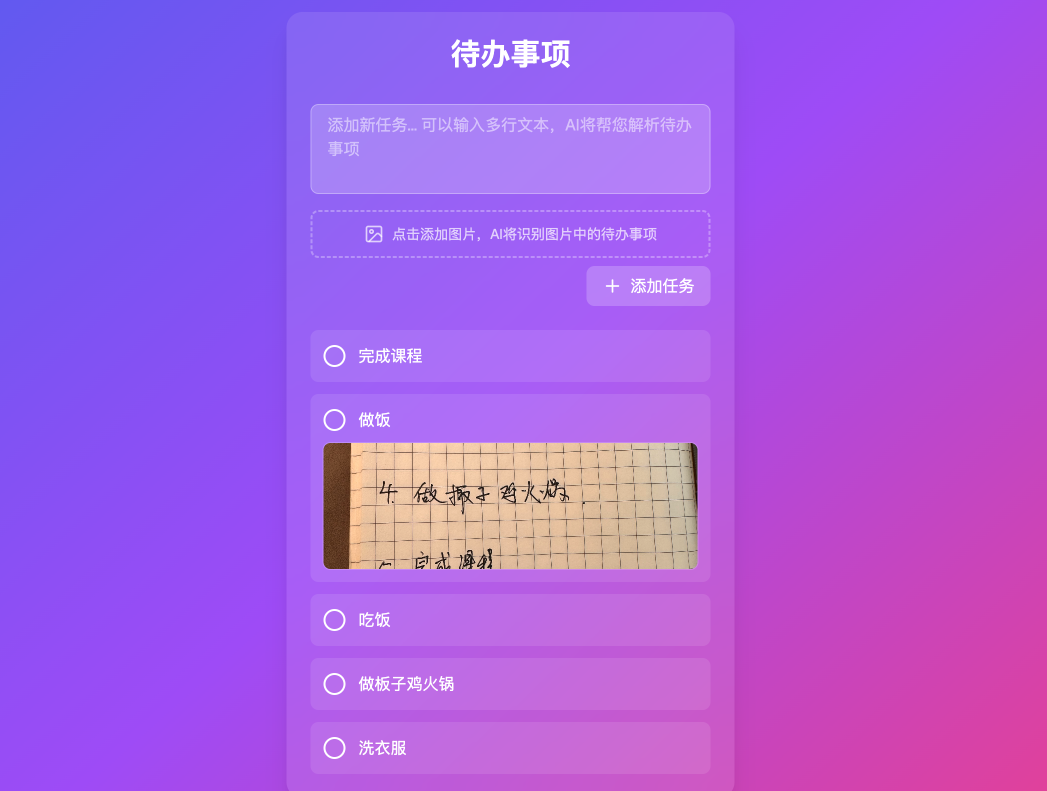
接下来我我们来测试一下我写的这个的实际效果,我尝试将我手写的这个内容,给到AI。看一下是否能够识别。

最终的识别效果,除了「椰子鸡火锅」识别成了「板子鸡火锅」之外,其他的识别效果都非常好
3.6 可能的错误
1. 400 timeout:
如果你遇到下面的问题,是由于通义模型访问supabase的图片超时导致的,你可以多少尝试几次。或者:
-
更换MemfireDB到中文环境
-
将上传图片的逻辑修改成为阿里云的对象存储
2. JSON解析错误:
JSON解析错误也是一个常见的错误,如果你遇到后,解决办法:
-
可以把错误告诉Cursor
-
修改提示词,约束返回的数据格式
四. 技术总结
可以看到,我们将这个待办事项修改成为AI版本的待办事项是非常方便的,我们只需要获取到一个APK_KEY,就可以像大模型服务商获取到AI能力。
下面我们也来分析一下核心的代码:
1. 初始化openai
这一步引入openai这这个库,初始化openai对象实例。
import OpenAI from "openai";
const openai = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, baseURL: process.env.OPENAI_BASE_URL,});我们明明使用的deepseek和qwen,为什么要使用openai?
-因为OpenAI的祖师爷地位,所以个大国内大模型厂商这两年接口都是兼容 OpenAI的接口的,所以我们可以直接使用OpenAl提供的JS库,非常方便。
2. 写提示词+模型
接下来我们就是需要写模型和系统提示词
//系统提示词const systemMessage = { role: "system" as const, content: "你是一个帮助用户提取待办事项的助手。请分析用户输入的文本或图片,识别出其中的待办事项。返回一个JSON对象,包含一个'todos'数组,数组中的每个项目都有一个'text'属性,包含单个待办事项。仅提取用户输入中的待办事项,不要添加任何额外内容,保持原始语言。", };
//模型const model = "qwen2.5-vl-72b-instruct"3. 调用AI服务
最后就是将model和系统提示词传入,并且传入对应的用户输入就好。这样我们就能获取到AI返回的服务
//调用ai服务completion = await openai.chat.completions.create({ model, messages: [ systemMessage, { role: "user" as const, content: [ ...(todoText.trim() ? [{ type: "text" as const, text: todoText }] : []), { type: "image_url" as const, image_url: { url: imageUrl } } ], } ], response_format: { type: "json_object" } });4. 处理AI返回的数据
接下来,我们就可以处理返回ai返回的数据。并且存放到我们的数据库中
const responseContent = completion.choices[0].message.content;const parsedResponse = JSON.parse(responseContent);const todoItems: { text: string }[] = parsedResponse.todos || [];
const insertPromises = todoItems.map((item: { text: string }, index: number) => supabaseAdmin .from("todos") .insert({ text: item.text, completed: false, user_id: userId, image_url: index === 0 ? imageUrl : null // Only add image to first todo }) );五. 项目源码
3. QwenVL版本(支持图像识别):源码下载链接